15,200 MIPS on AWS with Heirloom (Autoscaling an IBM Mainframe Application to 1,018 Transactions/Second)
January 1st, 2019
Introduction
If you are already muttering sweet phrases of disbelief at the headline, I understand, but hang in there!
The application used is a strict implementation of the TPC-C benchmark that was built for the IBM Mainframe using COBOL, BMS & CICS with a DB2 database. TPC-C is an online transaction processing (OLTP) benchmark that represents any industry that must manage, sell, or distribute a product or service.
Executive Summary
With Heirloom on AWS, IBM Mainframe applications that were monolithic, closed and scaled vertically, can be quickly & easily transformed (recompiled) so they are now agile, open and scaled horizontally.
This showcase clearly demonstrates the capability of Heirloom on AWS to deploy and dynamically scale a very large IBM Mainframe OLTP workload, with annual infrastructure cost savings of at least 90%.
The workload is deployed as an application that fully exploits the benefits of the cloud computing delivery model, such as application elasticity (the ability to automatically scale-out and scale-back), high availability (always accessible from anywhere at anytime), and pay-for-use (right-sized capacity for efficient resource utilization).
If your IBM Mainframe is an impediment to the execution of your strategic imperatives, contact us to learn how we can quickly & accurately transform your legacy workloads.
What We Did
First, we ran the TPC-C application on an IBM Mainframe to establish a baseline of transaction throughput per MIPS.
We then took the 50,000+ lines of the TPC-C application code & screens and compiled them (without any modifications) into 100% Java using the Heirloom SDK Eclipse plugin. The Java code was then packaged as a standard .war file, ready for deployment to any industry standard Java Application Server (such as Apache Tomcat). This process (from starting Eclipse to creating the .war file) can be done in 60 seconds (you can watch that happen in this video).
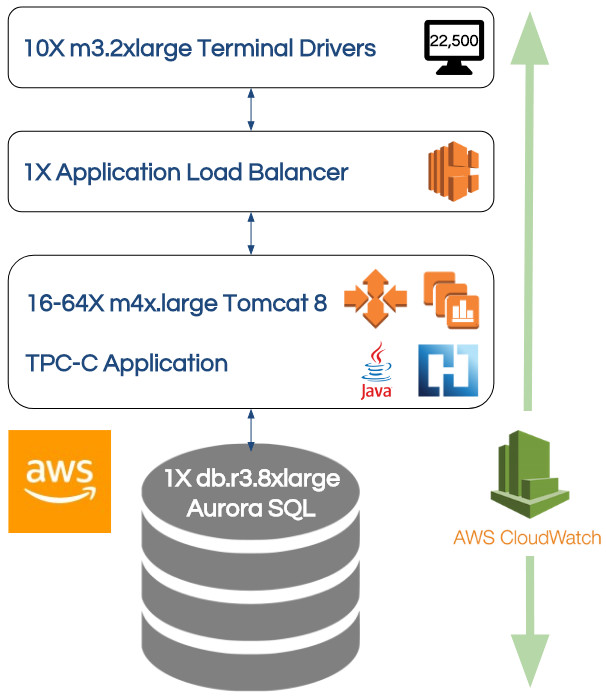
The .war file was deployed to the Amazon AWS platform described in the picture. The entire system runs inside AWS.
Briefly, the system comprises 5 primary layers:
- 22,500 simulated end-user terminals (think of 22,500 people simultaneously entering transactions into 3270 terminals).
- All concurrent transactions are distributed to application instances (in layer 3) by a single Amazon Application Load Balancer which automatically scales on-demand.
- The Heirloom TPC-C application layer is hosted in an Amazon Beanstalk environment consisting of a minimum of 16 Amazon EC2 instances (a Linux environment running Apache Tomcat). This environment automatically scales-out (by increments of 8), up to a maximum of 64 instances (depending on a metric of the average CPU utilization of the currently active instances). It also automatically scales-back when the load on the system decreases. For this application, the load is directly related to the number of active end-users on the system, and resource contention within the database. For enhanced reliability and availability, the instances are seamlessly distributed across 3 different availability zones (i.e. 3 different physical locations).
- The database (consisting of millions of rows of data in tables for districts, warehouses, items, stock-levels, new-orders etc) is hosted in an Amazon Aurora Database (which is both MySQL and PostgreSQL compatible).
- The application monitoring layer is provided by Amazon CloudWatch which provides a constant examination of the application instances and the AWS resources being utilized.
Execution Requirements
A valid TPC-C run must strictly adhere to the following primary requirements:
- All terminals must be operational before measuring transaction throughput (the “Warmup Time”).
- The system must run without error for a minimum period of 2 hours. This isn’t simply about getting all the terminals online and processing transactions. The design of TPC-C increases load on the database over time (including punishing table scan operations).
- At the end of the benchmark, response times on transactions in the 90th percentile range must be < 5s.
The Results
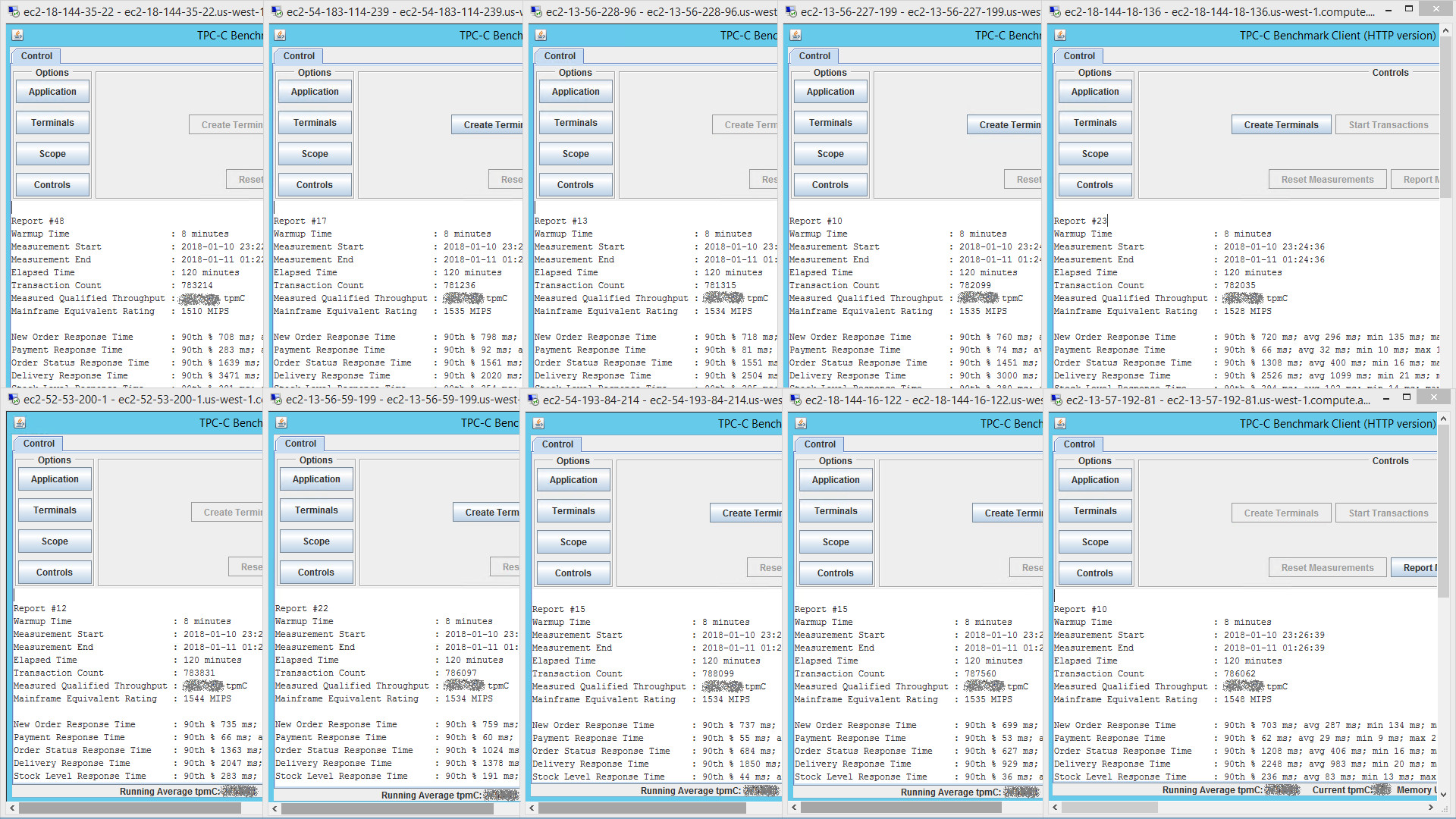
This image is of the 10 terminal drivers (each simulating 2,250 end-users) reporting results at the end of the TPC-C benchmark run. To see a bigger version of the image, right-click and open the image in a new tab.
All terminal drivers run in parallel, with each measuring transaction throughput for 2,250 terminals. These are added up to provide a total MIPS equivalent rating of over 15,200 MIPS.
The application workload (at peak scaling) was distributed over a total of 144 CPU cores (see details in FAQ below), which yields ~105 MIPS per CPU core. This is historically consistent with our client engagements, and a useful “rule of thumb” when looking at initial capacity planning.
Over the duration of the run, approx 7,820,000 end-user transactions were submitted.
7,820,000 / 128 minutes (incl. warmup time) / 60 = 1,018 transactions per second.
These are definitely not micro-transactions, so the transaction rate is mighty impressive. Especially considering the average response time for all transactions after 2 hours was still in the sub-second range.
Anticipatory FAQ
Why TPC-C?
Benchmarks from vendors are notoriously skewed. Pretty much, worthless.
TPC is an independent organization that has become an industry standard for measuring transaction throughput.
Why Heirloom?
Heirloom is the only platform that automatically refactors mainframe applications (online & batch) so they execute on Java Application Servers while preserving critical business logic, user interfaces, data integrity, and systems security.
The transformed application can continue to be developed in the original host language (COBOL, PL/I, JCL, etc), or in Java, or in any combination. You decide based on your objectives.
Why AWS?
Heirloom actually works on multiple clouds such as Pivotal Cloud Foundry, Google Cloud Platform, Microsoft Azure and Red Hat OpenShift, but we have had outstanding support from our partner Amazon in delivering this compelling mainframe-to-cloud showcase.
AWS provides an amazingly agile platform for easily deploying and managing auto-scaling workloads in a secure, reliable & available infrastructure. Powerful software services are aggregated to defined end-points that are seamlessly distributed to physical infrastructure in multiple data centers.
Can you provide more information on the AWS configuration?
Amazon lists EC2 instance types as having a number of vCPU’s. A vCPU is a virtualized core, not a physical core. However, a reasonable approximation is that 2 vCPU’s is presented from a single (hyperthreaded) physical CPU core.
i.e. 2 vCPU’s = 1 CPU core. We’re going to stick with physical CPU cores from here.
The scalable application layer (i.e. all the Tomcat Java Application Servers) consisted of a maximum of 64 m4x.large instances, each with 2 CPU cores. 128 in total.
The database layer (i.e. Amazon Aurora) was running on a single db.r4.8xlarge with 16 CPU cores.
So, excluding the terminal drivers (which in the real-world would simply be a browser tab on each end-users PC) and the load balancer, we have a system that can scale to a configured maximum of 144 CPU cores.
Why are the tpmC numbers masked in the results?
Reporting tpmC numbers without independent validation from TPC is a bit of a gray area, so we’ve erred on the side of caution and blurred it out. We’ve used an implementation of the TPC-C benchmark (because of its real-world characteristics) for comparative purposes only.
What about batch workloads?
Heirloom can scale batch workloads as well! It provides native support for JCL with its integrated Elastic Batch Platform (EBP) service. It has built-in clustering capabilities and integrates with various scheduling platforms via RESTful interfaces, including another service of Heirloom called Elastic Scheduling Platform (ESP). EBP runs on any standard Java Application Server and so seamlessly integrates with the AWS environment just as easily as the OLTP service.
Did you tune the IBM environment?
No. Neither did we tune the AWS environment. It’s certainly possible that tuning the mainframe environment could yield a better improvement than tuning the AWS environment, just as the reverse scenario is also possible. This is where benchmarking can get extremely contentious and extremely expensive. Respectfully, we’re not going there, as our assessment is that it will not fundamentally change the value proposition.
We use MSUs to size our IBM Mainframe, how does that relate?
MSU is a consumption-based measure and MIPS is a capacity-based measure, so hard to precisely compare. However, a reasonable “rule of thumb” is if you have a fully-utilized 6,000 MIPS mainframe, you would be consuming approximately 1,000 MSUs (i.e. a ratio of 6:1).
What’s the annual cost?
AWS
The vast majority of the infrastructure cost resides in the application and database layers. There are other costs such as load balancing and network traffic, but they are not relatively significant.
Let’s make the assumption that we’re running at the maximum configured capacity and 24×365 (which is unlikely). At peak load, we were using 64 m4.xlarge instances in the application layer, and 1 Aurora db.r4.8xlarge instance for the database.
Application layer (m4.xlarge): 64 * $0.20/hour * 24 * 365 = $112,128
Aurora database layer (db.r4.8xlarge): 1 * $4.64/hour * 24 * 365 = $40,646
Let’s add 10% (it’s definitely less than this) to cover other AWS costs. Other than the licensing cost of Heirloom, all the other software is included.
This gives us a total annual cost for the infrastructure of $168,050.
IBM Mainframe
We’re going to use some Gartner data that is in the public domain for this.
In 2009, Gartner figured out the total annual operating cost per IBM Mainframe MIPS was $4,496. In 2012, that number had reduced to $3,566, equivalent to an approximate reduction of 8% annually. Extrapolating that number through 2017 would give us a total operating cost per MIPS of $2,350.
15,200 MIPS * $2,350 = $35,720,000
In 2012, Gartner stated that hardware made up 14% of the total cost, and software made up 44% of the total cost. i.e. 58% of the total.
For 15,200 MIPS, this gives us a total annual cost for the infrastructure of $20,717,600.
That’s a pretty stark contrast to AWS (and this comparison doesn’t even factor in the staffing, automation, and maintenance cost benefits that are heavily in favor of the AWS infrastructure).
How much further can you go?
There is no indication of any significant constraints with increasing the capacity of the application layer. There’s tons of room to utilize more instances and much larger instance types.
Ultimately, the constraining factor with TPC-C (and OLTP workloads generally) will be the database. We have not yet leveraged the currently largest available Amazon Aurora instance (which is 2X bigger than the one we used in this showcase). From our work creating comparisons with other smaller Aurora instance types, it scales extremely well, so we would expect to see a significant increase in throughput.
We’re also looking forward to utilizing the upcoming Aurora Multi-Master release (which supports scale-out for both reads and writes).