Old Code is NOT Bad Code
Author Archive
-
December 5th, 2017
Old Code is NOT Bad Code
Voyager 1 fires thrusters for the first time in 37 years.
Running a proprietary assembler program written over 40 years ago, engineers at NASA were able to use the Voyager’s thrusters to replace the altitude correction engine that had degraded over the last 40 years. This extends the lifetime of the voyager 1 probe for another 2 or 3 years.
Is there a finer example than this that old code is not always bad code? Old code also continues to fulfill vital roles for NASA in the same way that it does for your business.
I did not start to write this article with the expectation that I would be comparing mainframe applications to rocket science, but when the facts fit…

Just like the incredible continuing value of the assembler code running on Voyager 1 let us take a moment to remember the incredible value of the code living on your mainframe.
Re-purposing hardware and executing decades-old code on it has significantly extended voyage 1’s life expectancy. We can use the same analogy for existing mainframe applications.
If we migrate the application using Heirloom, we are changing the hardware environment but keeping the existing code and giving it a new lease on life. This will extend the lifetime of these applications and actually increase their value to your company. Migrated applications do not just run in a new environment, their data, previously hidden away in an EBCDIC silo, suddenly becomes accessible to the rest of the enterprise. Imagine adding decades of experience in the form of your company’s data to a big data model designed to generate actionable business insights.
-
December 4th, 2017
CI/CD with COBOL and CICS
Introduction
Reading about Continuous Integration, Continuous Deployment (CI/CD), unit testing, etc., all seem a million miles away from daily life on the Mainframe.
In fact, there is a basic question to be answered for all projects, “Why do we need to do continuous integration?”. Agile guru Martin Fowler puts it best (he usually does) when he says:
Continuous Integration is a software development practice where members of a team integrate their work frequently; usually, each person integrates at least daily… Each integration is verified by an automated build… to detect integration errors as quickly as possible.
Large software projects are plagued with integration issues, developer 1 changes code and breaks developer 2’s code. If you are not following a continuous integration approach, this will only be discovered near release, resulting in many late nights for the developers and even more grey hairs for the project owners. It is at this point that coding standards fall precipitously, and “hacking” a change to “make it work” can ensure that the next project delivery starts with, often, severe technical debts. Unless you are the US government, this debt will have to be paid, resulting in longer release cycles and missing features.
At Heirloom, we develop our products and our code every single day following industry best practices and are extremely proud to call ourselves agile.
That’s great for Heirloom as a commercial software development company producing a completely automated mainframe workload migration platform, but what about our customers?
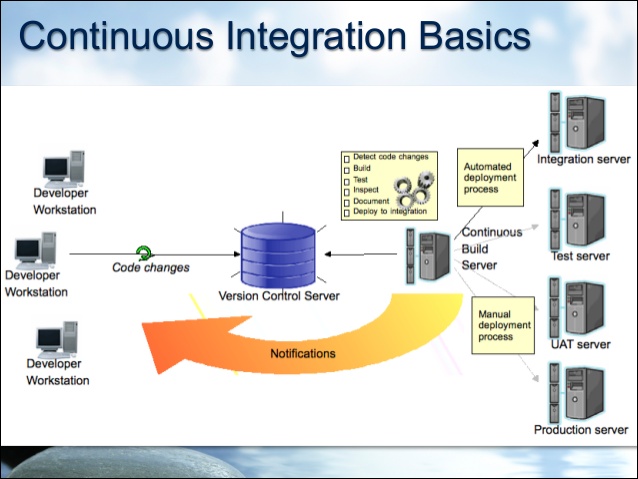
Well, our tooling enables our customer’s mainframe code to fit into industry best practice CI/CD environments and processes just like the one below. Because mainframe code compiled with Heirloom runs on the Java VM, we are in a great position that we can utilize all the Java infrastructure that has been built in the last few years to support enterprise application development.
How Do We Implement This?
Let’s start with the developer workstation. Heirloom is delivered as both a development environment and a Java framework.
The development environment is an Eclipse perspective. We add COBOL and PL/1 as fully supported languages to the industry-standard Eclipse development environment.
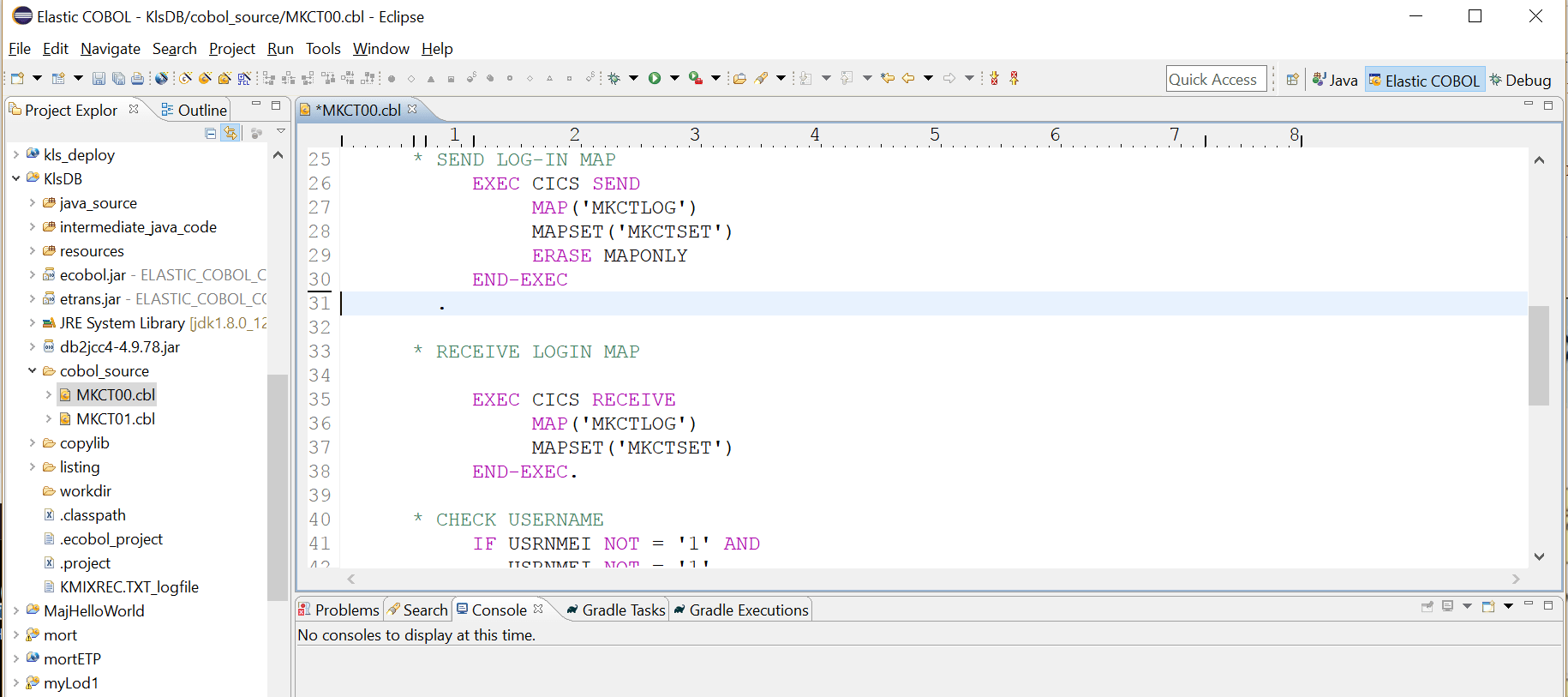
We can follow a full development cycle here:
Edit … Compile … Debug … Test … Commit
The code being worked on in the image above is a standard CICS application presenting a BMS screen to the user. With Heirloom, BMS screen definitions are automatically transformed into HTML5 templates, with the initial template design mimicking the green screen that mainframe users are familiar with. See an earlier post for a typical green screen sample program Mainframe Migration? Why?
The version control system (VCS) that we use at Heirloom is Gitlab (we used Bitbucket before that, and our clients have used similar hosted services or their own internal repositories).
The Continuous Build Server that we use runs the Jenkins open-source automation server.
All our notifications back to the developers are done using Slack channels.
So what is the process flow?
- Developer makes and tests code changes in eclipse and commits them to the VCS
- A notification is sent to a slack channel, visible to all developers

- The Jenkins server is also notified of the change, checks the code out of the repository, and starts the build, test, and deploy process. Our build pipeline looks like this:
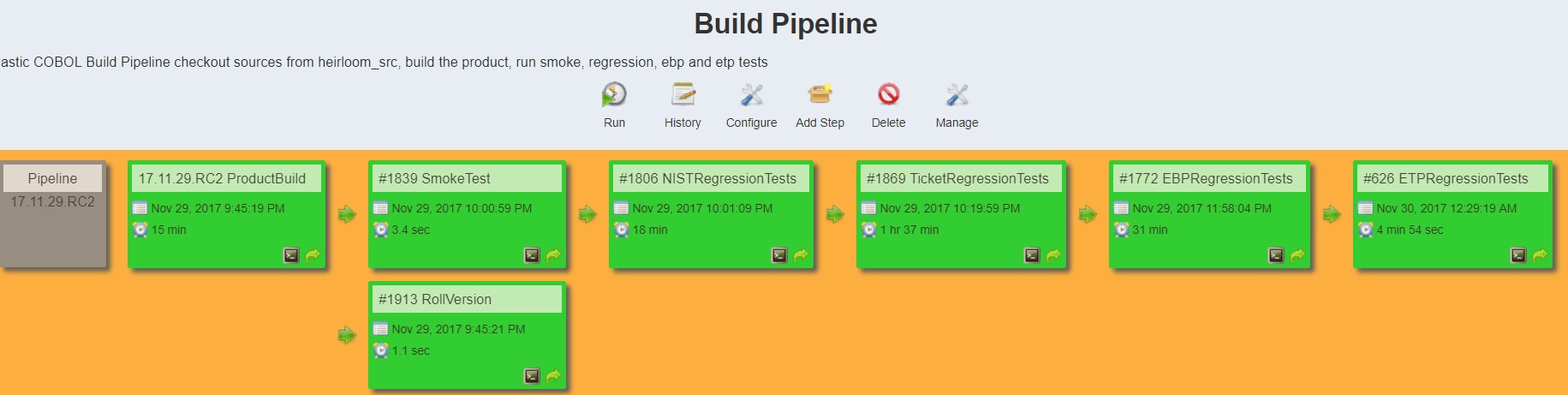
- When all the tests are run, Jenkins pushes the newly created artifacts to our overnight build area and creates versioned artifacts in a maven repository. Jenkins then notifies the developers that the build was good (or not) on a different slack channel.

Summary
Heirloom migrates not just your mainframe code to a new platform, the Java VM. It also enables you to transform your developer and integration processes. When you use Heirloom, your mainframe projects and developers are now citizens of the open systems world and can adopt industry best practices for continuous integration and deployment.
A pre-requisite that many people may have noticed for all this to work is that there is a set of tests that can be run automatically as part of the build and integration process, and that is the topic for the next article.
-
November 29th, 2017
Mainframe Migration? Why?
This article investigates why organizations should consider Mainframe Migration, the migration options they have, and the steps they need to take to transform their mainframe workloads to run on the cloud.
Let’s set the scene a little bit for a typical large organization that runs business-critical applications on the mainframe.
- Your mainframe and your mainframe applications just run.
- It causes no heartache, no troubles; when was the last time it “went down”?
- If it weren’t for the pesky leasing payments and the endless contract renewal discussions, you probably wouldn’t give it too much thought.
But there are a few vague, uneasy feelings:
- Perhaps you are not as responsive to your customers’ requirements as you could be.
- At month-end, quarter-end, and year-end, the batch jobs are only just completed within the batch window.
- There are a lot of grey beards in the PL/1, COBOL teams
- Adding a new type of customer contract takes months with the mainframe screens and seemingly minutes with the web team.
- Let’s face it a green screen does not have the possibility to represent data that a modern web browser supports
Would you rather be working with this green screen? A COBOL/CICS application that has been deployed to Pivotal Cloud Foundry using Heirloom.
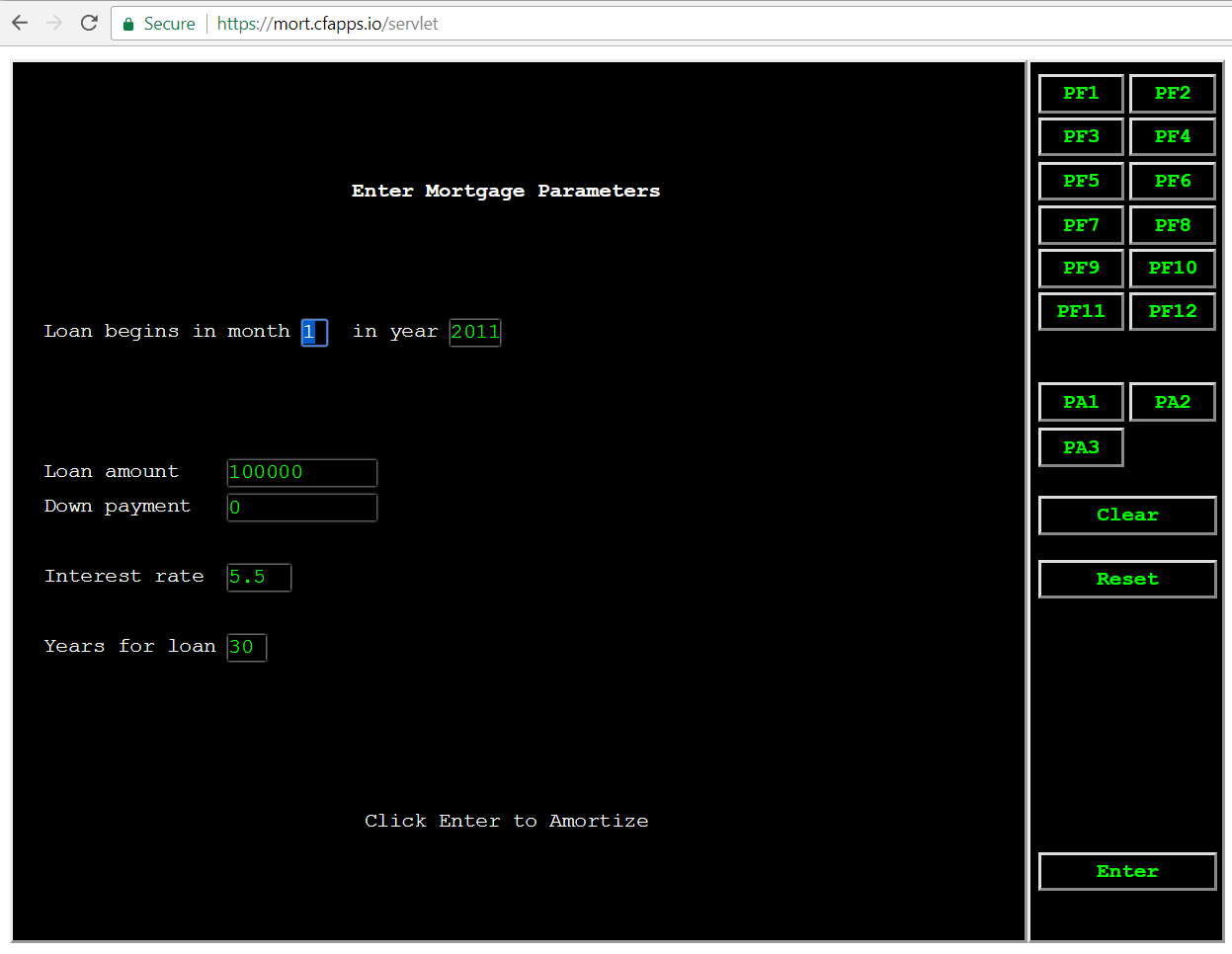
Or with this Angular and D3 application that is also running on Pivotal Cloud Foundry and using exactly the same back-end COBOL/CICS program to run the amortization calculation?

Your company’s “front-end” applications are being delivered using industry best practices, continuous integration, and continuous deployment, CI/CD of the applications is de rigueur, and perhaps most importantly, your customers are extremely happy with the features, the responsiveness, and the look and feel. These applications and the teams that create them are agile in a way that the Mainframe group is not.
At the same time, these web applications are now capable of the same reliability as your mainframe environment, not because every single component works all the time but because every component has fail-over redundancy built-in. It is a different reliability model but one to which the organization is gradually becoming accustomed.
Your company is also becoming accustomed to hardware costs for running the non-mainframe applications to actually fall each year and yet still eke out higher and higher performance. Need to have a little performance kick for black Friday? Just automatically scale out some more application instances, and pay for the extra throughput performance ONLY when it is needed.
So now the scene is set, check back here for the next post, where I will lay out various Mainframe Migration options and the pros and cons of each one.