15,200 MIPS on AWS with Heirloom (Autoscaling an IBM Mainframe Application to 1,018 Transactions/Second)
Archive for the ‘Blog’ Category
-
January 1st, 2019
15,200 MIPS on AWS with Heirloom (Autoscaling an IBM Mainframe Application to 1,018 Transactions/Second)

Movie: Plan 9 from Outer Space Introduction
If you are already muttering sweet phrases of disbelief at the headline, I understand, but hang in there!
The application used is a strict implementation of the TPC-C benchmark that was built for the IBM Mainframe using COBOL, BMS & CICS with a DB2 database. TPC-C is an online transaction processing (OLTP) benchmark that represents any industry that must manage, sell, or distribute a product or service.
Executive Summary
With Heirloom on AWS, IBM Mainframe applications that were monolithic, closed and scaled vertically, can be quickly & easily transformed (recompiled) so they are now agile, open and scaled horizontally.
This showcase clearly demonstrates the capability of Heirloom on AWS to deploy and dynamically scale a very large IBM Mainframe OLTP workload, with annual infrastructure cost savings of at least 90%.
The workload is deployed as an application that fully exploits the benefits of the cloud computing delivery model, such as application elasticity (the ability to automatically scale-out and scale-back), high availability (always accessible from anywhere at anytime), and pay-for-use (right-sized capacity for efficient resource utilization).
If your IBM Mainframe is an impediment to the execution of your strategic imperatives, contact us to learn how we can quickly & accurately transform your legacy workloads.
What We Did
First, we ran the TPC-C application on an IBM Mainframe to establish a baseline of transaction throughput per MIPS.
We then took the 50,000+ lines of the TPC-C application code & screens and compiled them (without any modifications) into 100% Java using the Heirloom SDK Eclipse plugin. The Java code was then packaged as a standard .war file, ready for deployment to any industry standard Java Application Server (such as Apache Tomcat). This process (from starting Eclipse to creating the .war file) can be done in 60 seconds (you can watch that happen in this video).
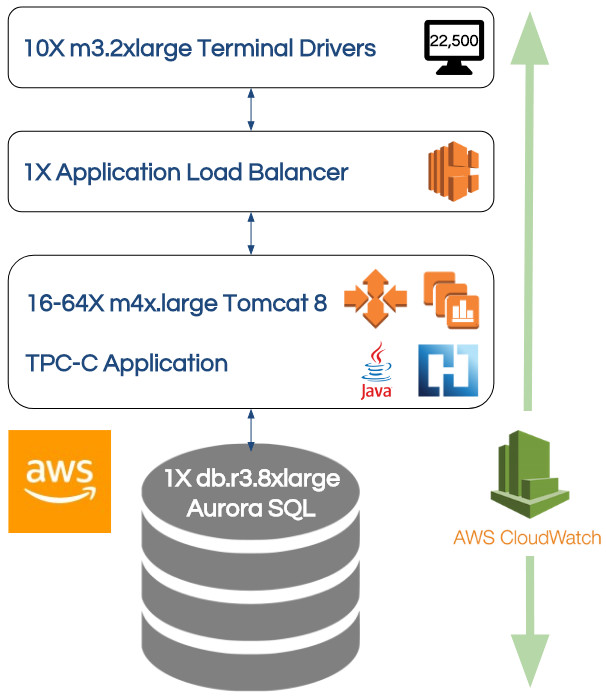
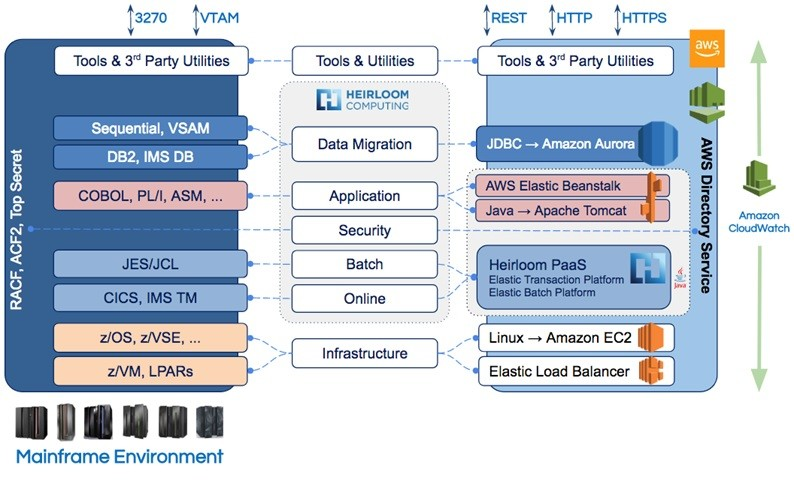
The .war file was deployed to the Amazon AWS platform described in the picture. The entire system runs inside AWS.
Briefly, the system comprises 5 primary layers:
- 22,500 simulated end-user terminals (think of 22,500 people simultaneously entering transactions into 3270 terminals).
- All concurrent transactions are distributed to application instances (in layer 3) by a single Amazon Application Load Balancer which automatically scales on-demand.
- The Heirloom TPC-C application layer is hosted in an Amazon Beanstalk environment consisting of a minimum of 16 Amazon EC2 instances (a Linux environment running Apache Tomcat). This environment automatically scales-out (by increments of 8), up to a maximum of 64 instances (depending on a metric of the average CPU utilization of the currently active instances). It also automatically scales-back when the load on the system decreases. For this application, the load is directly related to the number of active end-users on the system, and resource contention within the database. For enhanced reliability and availability, the instances are seamlessly distributed across 3 different availability zones (i.e. 3 different physical locations).
- The database (consisting of millions of rows of data in tables for districts, warehouses, items, stock-levels, new-orders etc) is hosted in an Amazon Aurora Database (which is both MySQL and PostgreSQL compatible).
- The application monitoring layer is provided by Amazon CloudWatch which provides a constant examination of the application instances and the AWS resources being utilized.
Execution Requirements
A valid TPC-C run must strictly adhere to the following primary requirements:
- All terminals must be operational before measuring transaction throughput (the “Warmup Time”).
- The system must run without error for a minimum period of 2 hours. This isn’t simply about getting all the terminals online and processing transactions. The design of TPC-C increases load on the database over time (including punishing table scan operations).
- At the end of the benchmark, response times on transactions in the 90th percentile range must be < 5s.
The Results
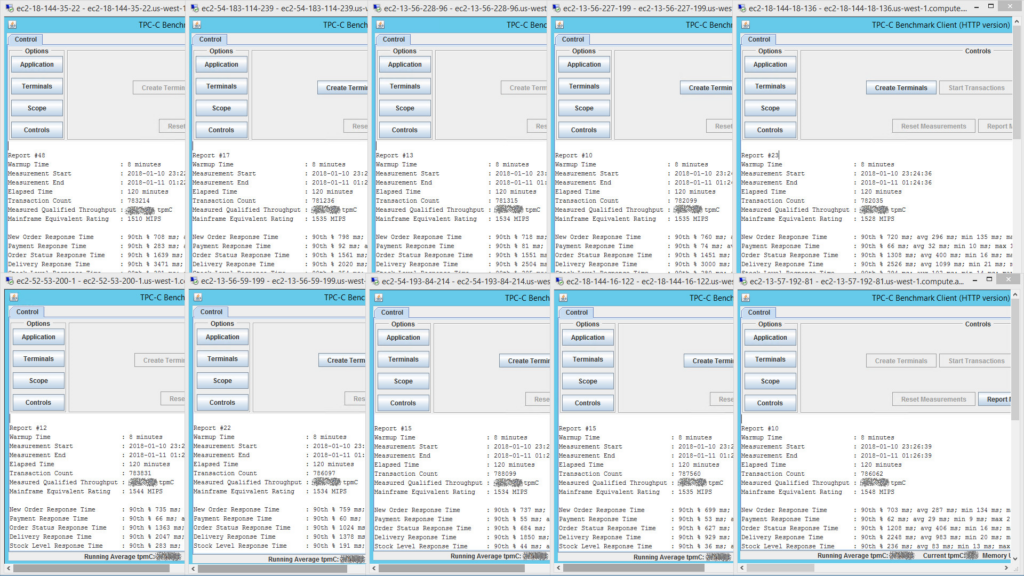
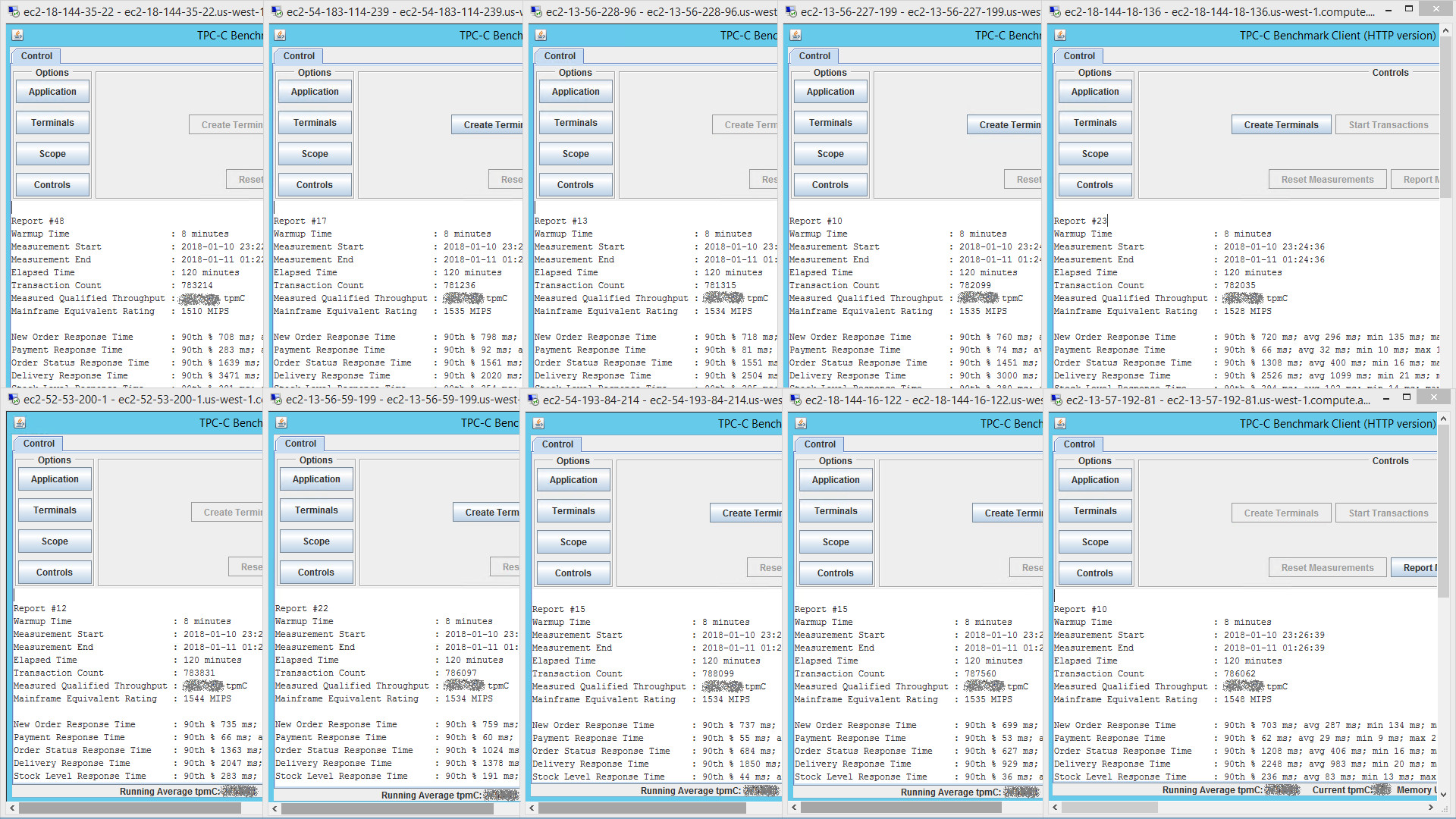
This image is of the 10 terminal drivers (each simulating 2,250 end-users) reporting results at the end of the TPC-C benchmark run. To see a bigger version of the image, right-click and open the image in a new tab.
All terminal drivers run in parallel, with each measuring transaction throughput for 2,250 terminals. These are added up to provide a total MIPS equivalent rating of over 15,200 MIPS.
The application workload (at peak scaling) was distributed over a total of 144 CPU cores (see details in FAQ below), which yields ~105 MIPS per CPU core. This is historically consistent with our client engagements, and a useful “rule of thumb” when looking at initial capacity planning.
Over the duration of the run, approx 7,820,000 end-user transactions were submitted.
7,820,000 / 128 minutes (incl. warmup time) / 60 = 1,018 transactions per second.
These are definitely not micro-transactions, so the transaction rate is mighty impressive. Especially considering the average response time for all transactions after 2 hours was still in the sub-second range.
Anticipatory FAQ
Why TPC-C?
Benchmarks from vendors are notoriously skewed. Pretty much, worthless.
TPC is an independent organization that has become an industry standard for measuring transaction throughput.
Why Heirloom?
Heirloom is the only platform that automatically refactors mainframe applications (online & batch) so they execute on Java Application Servers while preserving critical business logic, user interfaces, data integrity, and systems security.
The transformed application can continue to be developed in the original host language (COBOL, PL/I, JCL, etc), or in Java, or in any combination. You decide based on your objectives.
Why AWS?
Heirloom actually works on multiple clouds such as Pivotal Cloud Foundry, Google Cloud Platform, Microsoft Azure and Red Hat OpenShift, but we have had outstanding support from our partner Amazon in delivering this compelling mainframe-to-cloud showcase.
AWS provides an amazingly agile platform for easily deploying and managing auto-scaling workloads in a secure, reliable & available infrastructure. Powerful software services are aggregated to defined end-points that are seamlessly distributed to physical infrastructure in multiple data centers.
Can you provide more information on the AWS configuration?
Amazon lists EC2 instance types as having a number of vCPU’s. A vCPU is a virtualized core, not a physical core. However, a reasonable approximation is that 2 vCPU’s is presented from a single (hyperthreaded) physical CPU core.
i.e. 2 vCPU’s = 1 CPU core. We’re going to stick with physical CPU cores from here.
The scalable application layer (i.e. all the Tomcat Java Application Servers) consisted of a maximum of 64 m4x.large instances, each with 2 CPU cores. 128 in total.
The database layer (i.e. Amazon Aurora) was running on a single db.r4.8xlarge with 16 CPU cores.
So, excluding the terminal drivers (which in the real-world would simply be a browser tab on each end-users PC) and the load balancer, we have a system that can scale to a configured maximum of 144 CPU cores.
Why are the tpmC numbers masked in the results?
Reporting tpmC numbers without independent validation from TPC is a bit of a gray area, so we’ve erred on the side of caution and blurred it out. We’ve used an implementation of the TPC-C benchmark (because of its real-world characteristics) for comparative purposes only.
What about batch workloads?
Heirloom can scale batch workloads as well! It provides native support for JCL with its integrated Elastic Batch Platform (EBP) service. It has built-in clustering capabilities and integrates with various scheduling platforms via RESTful interfaces, including another service of Heirloom called Elastic Scheduling Platform (ESP). EBP runs on any standard Java Application Server and so seamlessly integrates with the AWS environment just as easily as the OLTP service.
Did you tune the IBM environment?
No. Neither did we tune the AWS environment. It’s certainly possible that tuning the mainframe environment could yield a better improvement than tuning the AWS environment, just as the reverse scenario is also possible. This is where benchmarking can get extremely contentious and extremely expensive. Respectfully, we’re not going there, as our assessment is that it will not fundamentally change the value proposition.
We use MSUs to size our IBM Mainframe, how does that relate?
MSU is a consumption-based measure and MIPS is a capacity-based measure, so hard to precisely compare. However, a reasonable “rule of thumb” is if you have a fully-utilized 6,000 MIPS mainframe, you would be consuming approximately 1,000 MSUs (i.e. a ratio of 6:1).
What’s the annual cost?
AWS
The vast majority of the infrastructure cost resides in the application and database layers. There are other costs such as load balancing and network traffic, but they are not relatively significant.
Let’s make the assumption that we’re running at the maximum configured capacity and 24×365 (which is unlikely). At peak load, we were using 64 m4.xlarge instances in the application layer, and 1 Aurora db.r4.8xlarge instance for the database.
Application layer (m4.xlarge): 64 * $0.20/hour * 24 * 365 = $112,128
Aurora database layer (db.r4.8xlarge): 1 * $4.64/hour * 24 * 365 = $40,646
Let’s add 10% (it’s definitely less than this) to cover other AWS costs. Other than the licensing cost of Heirloom, all the other software is included.
This gives us a total annual cost for the infrastructure of $168,050.
IBM Mainframe
We’re going to use some Gartner data that is in the public domain for this.
In 2009, Gartner figured out the total annual operating cost per IBM Mainframe MIPS was $4,496. In 2012, that number had reduced to $3,566, equivalent to an approximate reduction of 8% annually. Extrapolating that number through 2017 would give us a total operating cost per MIPS of $2,350.
15,200 MIPS * $2,350 = $35,720,000
In 2012, Gartner stated that hardware made up 14% of the total cost, and software made up 44% of the total cost. i.e. 58% of the total.
For 15,200 MIPS, this gives us a total annual cost for the infrastructure of $20,717,600.
That’s a pretty stark contrast to AWS (and this comparison doesn’t even factor in the staffing, automation, and maintenance cost benefits that are heavily in favor of the AWS infrastructure).
How much further can you go?
There is no indication of any significant constraints with increasing the capacity of the application layer. There’s tons of room to utilize more instances and much larger instance types.
Ultimately, the constraining factor with TPC-C (and OLTP workloads generally) will be the database. We have not yet leveraged the currently largest available Amazon Aurora instance (which is 2X bigger than the one we used in this showcase). From our work creating comparisons with other smaller Aurora instance types, it scales extremely well, so we would expect to see a significant increase in throughput.
We’re also looking forward to utilizing the upcoming Aurora Multi-Master release (which supports scale-out for both reads and writes).
-
September 1st, 2018
Breaking the Monolith: Creating Serverless Functions (Microservices) from an IBM Mainframe Application (Done In 60 Seconds)

A scene from the movie: Gone In 60 Seconds (Touchstone Pictures & Jerry Bruckheimer Films) Square Pegs in Round Holes
I understand; you may already be skeptical. The application modernization arena has not done itself any favors with years of vendor misdirection and misleading claims (permeating from whitepapers and glossy write-ups that attempt to recast tired proprietary technology as modern & relevant — square pegs in round holes). We encounter that hurdle with every new client. Often, they are exasperated; so we simply show them exactly how we modernize their code using open software and the sense of mistrust quickly evaporates, replaced by the understanding that Heirloom can make their trusted legacy applications, agile. In the same vein, I am going to show you how Heirloom can take a function from a monolithic IBM Mainframe COBOL/CICS application and deploy it to a serverless environment as a microservice (using AWS Lambda coupled with the recent release of AWS Lambda Layers).
What is Heirloom?
Heirloom is already the industry-leading solution for refactoring IBM Mainframe applications to the cloud. It is the only solution that was built for the cloud, delivering cloud-native deployment by automatically & accurately transforming online and batch COBOL & PL/I applications to 100% Java.
In 2018, we worked with Amazon to refactor an industry-standard TPC-C transaction processing benchmark written in COBOL/CICS from the IBM Mainframe to AWS Elastic Beanstalk, delivering 1,018 transactions per second — equivalent to the processing capacity of a large 15,200 MIPS IBM Mainframe — with a dramatically reduced annual infrastructure cost of $365K vs $16M. You can read more about this showcase on Amazon’s APN site.
What is Serverless Computing?
Beyond instance-oriented infrastructures (like AWS Elastic Beanstalk), are serverless compute/store infrastructures (like AWS Lambda) that deploy discreet functions as microservices.
With serverless computing, you run code without provisioning or managing servers (zero administration effort), required resources are continuously scaled (automatically), and costs are only incurred when your code is running (measured in sub-seconds).
Microservices provide a model for delivering high-quality applications that are agile, scalable, and available.
Breaking an IBM Mainframe Monolith into a Microservice
In the video below, we start with an IBM Mainframe COBOL/CICS application that has been refactored with Heirloom and is now running under a local instance of a Java Application Server (Apache Tomcat). The next steps taken with Heirloom to extract, create and deploy the microservice are:
- Create the application layer: The Heirloom “Facade Factory” is used to extract and refactor the “Get Credit Limit” logic from the monolithic application, as a discreet callable function (encapsulated in a Java jar package), and deployed as an AWS Lambda Layer (this is the “getAccount” application layer).
- Create the AWS Lambda service: We overlay a simple AWS Lambda service sample with the code to call “getAccount” with its defined inputs, and process the output (this is the “AccountLimit” service).
- Construct the microservice: Finally, we associate the “AccountLimit” service with the “getAccount” (application) layer and the Heirloom AWS Lambda (runtime) layer.
The combination of these components represents the entirety of the microservice stack. More simply stated, the stack looks like this:
[client] — invoke the microservice [AWS Lambda Service: AccountLimit] — service interface [AWS Lambda Layer: getAccount] — facade and extracted function [AWS Lambda Layer: Heirloom runtime] — Java framework for executing mainframe appsThe Heirloom AWS Lambda runtime layer provides everything you need to deploy microservices derived from your online and batch IBM Mainframe applications. It’s much more than just a language runtime — it’s a mainframe platform (implemented as a Java framework).
In summary, Heirloom can quickly & accurately refactor your IBM Mainframe applications to agile cloud infrastructures like AWS Elastic Beanstalk, Azure App Service, Pivotal Cloud Foundry, Red Hat OpenShift & Google Cloud Platform.
It can also enable & accelerate your transformation from monolithic application architectures to microservices running on serverless computing infrastructures like AWS Lambda.
-
June 1st, 2018
IBM Mainframe Security To LDAP (Done In 60 Seconds)

TL;DR — watch this video to see how IBM workload transformation with Heirloom enables you to fully replicate your IBM Mainframe application security controls.
So far in our “Done In 60 Seconds” series, we have covered application migration (automatically transforming an unmodified Mainframe COBOL/CICS/VSAM application to a Java Application Server & Relational DB) and data migration (migrating a Mainframe VSAM file to a Relational DB without changing the application source).
In this article, we are putting the spotlight on application security. The IBM Mainframe has acquired the reputation of being a highly secure application platform, primarily because of its ability to manage & control access to application-specific resources. These “rules” and “policies” have a considerable impact on prescribed operational processes related to the application workload, and so it is vital that they can be easily replicated on the target platform. In 60 seconds, here’s how it’s done with Heirloom:
With integrated support for user-authentication and resource-authorization in Heirloom, existing rules are extracted from the host system (e.g. RACF) and precisely replicated in any industry-standard LDAP server (including open-source implementations such as Apache DS), without requiring any changes to the application code.

Application security should not (as it often is) be relegated to a sideline consideration during (or even, post) a transformation project. Doing so injects a lot of unnecessary risks, and yet many modernization vendors fail to fully address this critical piece of the puzzle.
Mainframe applications (batch and online) often rely on fine-grained resource-authorization (not just user-authentication), and the transformed application should provide the same controls, without requiring any code changes, to guarantee enforcement of existing security policies via integration with industry-standard directory services.
Finally, because applications transformed with Heirloom are 100% Java, transport-security (secure communications) and platform-security (safe deployment of application resources) is easily achieved via seamless integration with Java Application Servers.
-
March 1st, 2018
Mainframe VSAM to Relational DB (Done In 60 Seconds)
In my previous article, we showed you how Heirloom can automatically transform a complex mainframe warehousing application and deploy it to a Java Application Server in 60 seconds with 100% accuracy, guaranteed.
Since we’ve already showcased what we can do with application code & logic, we’re now going to take a look at what Heirloom does for data transformation. Again, it will only take 60 seconds so keep that in mind when you’ve watched the video and taken a breath to consider the benefits of transforming proprietary mainframe data stores into accessible relational databases.
So, what happened? We took a VSAM KSDS file encoded as EBCDIC from the mainframe, analyzed the record structure, and used that XML representation to extract, transform and load the data into a PostgreSQL database table encoded in ASCII. The application was then executed without any changes to the source code (so yes, we were using the applications existing COBOL I/O statements to seamlessly access the relational data).

The application knows nothing of this wonderous outcome and “believes” it is still grinding through a VSAM file that is still blessed with packed decimals & redefined record structures. Heaven. Shhh, we won’t tell if you don’t.
Further, because the data is now in a relational store, we can easily establish views to make the data visible to other applications that need to interrogate the data via SQL.
When migrating mainframe workloads, data is often overlooked along with other areas such as batch processing, security, deployment, cloud, DevOps, UI modernization, and application refactoring. Heirloom is the only platform in the market that fully addresses each of these critical components. Something that we will continue to make clear over the coming weeks. And don’t forget, with Heirloom, migrated workloads are 100% Java deployed to any industry-standard Java Application Server (e.g. Apache Tomcat).
-
January 1st, 2018
Application Transformation (Done In 60 Seconds)
Mainframe COBOL/CICS/VSAM to Java Application Server & Relational DB
TL;DR — Watch the video below to see how Heirloom automatically takes a complex mainframe warehousing application to Java in 60 seconds with 100% accuracy, guaranteed.
Migrating mainframe workloads to anywhere is hard, right?

You may have seen vendor presentations that promise an assured migration process, led by analysis tools that paint interrelationships between application artifacts that bedazzle (mislead) you into believing that the complexity is well understood.
It’s also blatant vendor misdirection. The hard part is in the migration, not the analysis.
What you are seeing is superficial at best. A “shiny object” that distracts you from the complexity ahead, and one that steers you towards an expensive multi-year services-led engagement that is aligned with the vendor’s business model, not yours.
Just ask the vendor, “where does the application get deployed?”. If the answer is not “any Java Application Server“, you are being quietly led into a dependency on a labyrinthic proprietary black-box that underpins an enforced application software architecture (e.g. MVC). Any assertions that you are now on an agile, open, scalable, performant platform, die right there.
I’m not going to get into an extensive takedown (in this article) of why migration transformation toolsets that are borne of application analyzers are a hugely expensive strategic misstep because I’d like you to spend the next 60 seconds watching how astoundingly fast Heirloom is at transforming mainframe applications to Java.
Need a recap? What you saw was a mainframe COBOL/CICS implementation of the TPC-C benchmark (an application with over 50,000 LOC and 7 BMS screens) being compiled by Heirloom (without any code changes) and deployed to a Java Application Server for immediate execution via a browser. All the data for this application was previously migrated from VSAM (EBCDIC encoded) to an RDBMS (ASCII encoded). In later articles, we’ll demonstrate how Heirloom migrates mainframe batch, data, and security profiles just as quickly.
Although the resulting application is 100% Java (and deployable on-premise or to any cloud), Heirloom provides full support (via Eclipse plug-ins) for on-going development of the application in the host language (COBOL in this example, but PL/I also) or in the target language (i.e. Java), or both. This was done because any transformation is not just about the application artifacts. People are obviously a big part of the IP equation, and securing the engagement of IT staff is essential to ensure a successful transformation. Not just on day 1, but for many years post-deployment.
-
December 5th, 2017
Old Code is NOT Bad Code
Voyager 1 fires thrusters for the first time in 37 years.
Running a proprietary assembler program written over 40 years ago, engineers at NASA were able to use the Voyager’s thrusters to replace the altitude correction engine that had degraded over the last 40 years. This extends the lifetime of the voyager 1 probe for another 2 or 3 years.
Is there a finer example than this that old code is not always bad code? Old code also continues to fulfill vital roles for NASA in the same way that it does for your business.
I did not start to write this article with the expectation that I would be comparing mainframe applications to rocket science, but when the facts fit…

Just like the incredible continuing value of the assembler code running on Voyager 1 let us take a moment to remember the incredible value of the code living on your mainframe.
Re-purposing hardware and executing decades-old code on it has significantly extended voyage 1’s life expectancy. We can use the same analogy for existing mainframe applications.
If we migrate the application using Heirloom, we are changing the hardware environment but keeping the existing code and giving it a new lease on life. This will extend the lifetime of these applications and actually increase their value to your company. Migrated applications do not just run in a new environment, their data, previously hidden away in an EBCDIC silo, suddenly becomes accessible to the rest of the enterprise. Imagine adding decades of experience in the form of your company’s data to a big data model designed to generate actionable business insights.
-
December 4th, 2017
CI/CD with COBOL and CICS
Introduction
Reading about Continuous Integration, Continuous Deployment (CI/CD), unit testing, etc., all seem a million miles away from daily life on the Mainframe.
In fact, there is a basic question to be answered for all projects, “Why do we need to do continuous integration?”. Agile guru Martin Fowler puts it best (he usually does) when he says:
Continuous Integration is a software development practice where members of a team integrate their work frequently; usually, each person integrates at least daily… Each integration is verified by an automated build… to detect integration errors as quickly as possible.
Large software projects are plagued with integration issues, developer 1 changes code and breaks developer 2’s code. If you are not following a continuous integration approach, this will only be discovered near release, resulting in many late nights for the developers and even more grey hairs for the project owners. It is at this point that coding standards fall precipitously, and “hacking” a change to “make it work” can ensure that the next project delivery starts with, often, severe technical debts. Unless you are the US government, this debt will have to be paid, resulting in longer release cycles and missing features.
At Heirloom, we develop our products and our code every single day following industry best practices and are extremely proud to call ourselves agile.
That’s great for Heirloom as a commercial software development company producing a completely automated mainframe workload migration platform, but what about our customers?
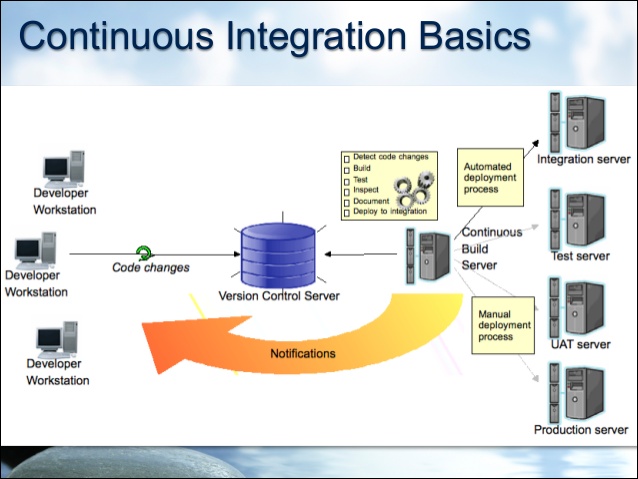
Well, our tooling enables our customer’s mainframe code to fit into industry best practice CI/CD environments and processes just like the one below. Because mainframe code compiled with Heirloom runs on the Java VM, we are in a great position that we can utilize all the Java infrastructure that has been built in the last few years to support enterprise application development.
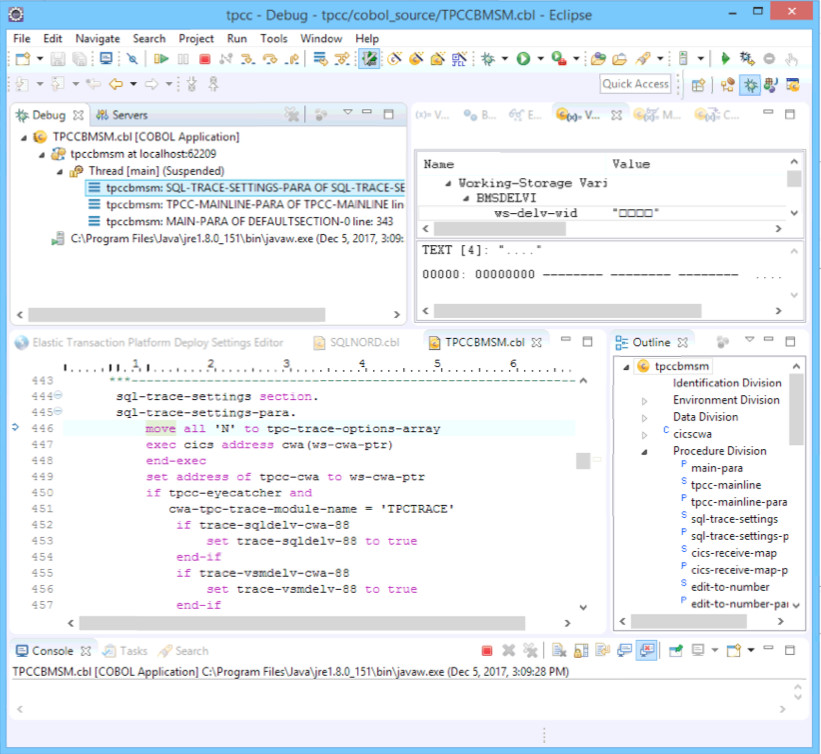
How Do We Implement This?
Let’s start with the developer workstation. Heirloom is delivered as both a development environment and a Java framework.
The development environment is an Eclipse perspective. We add COBOL and PL/1 as fully supported languages to the industry-standard Eclipse development environment.
We can follow a full development cycle here:
Edit … Compile … Debug … Test … Commit
The code being worked on in the image above is a standard CICS application presenting a BMS screen to the user. With Heirloom, BMS screen definitions are automatically transformed into HTML5 templates, with the initial template design mimicking the green screen that mainframe users are familiar with. See an earlier post for a typical green screen sample program Mainframe Migration? Why?
The version control system (VCS) that we use at Heirloom is Gitlab (we used Bitbucket before that, and our clients have used similar hosted services or their own internal repositories).
The Continuous Build Server that we use runs the Jenkins open-source automation server.
All our notifications back to the developers are done using Slack channels.
So what is the process flow?
- Developer makes and tests code changes in eclipse and commits them to the VCS
- A notification is sent to a slack channel, visible to all developers

- The Jenkins server is also notified of the change, checks the code out of the repository, and starts the build, test, and deploy process. Our build pipeline looks like this:
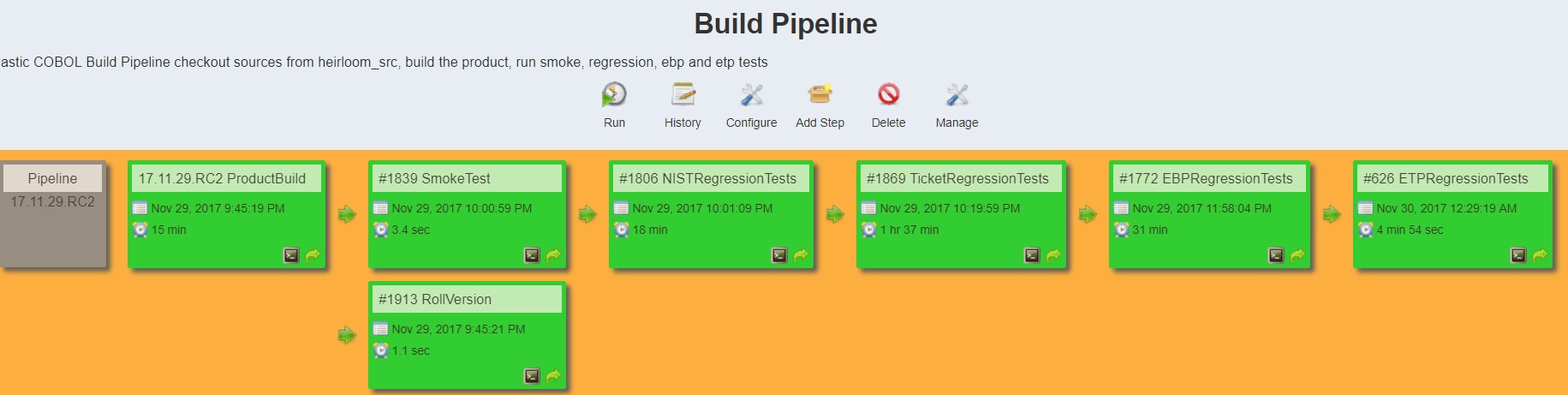
- When all the tests are run, Jenkins pushes the newly created artifacts to our overnight build area and creates versioned artifacts in a maven repository. Jenkins then notifies the developers that the build was good (or not) on a different slack channel.

Summary
Heirloom migrates not just your mainframe code to a new platform, the Java VM. It also enables you to transform your developer and integration processes. When you use Heirloom, your mainframe projects and developers are now citizens of the open systems world and can adopt industry best practices for continuous integration and deployment.
A pre-requisite that many people may have noticed for all this to work is that there is a set of tests that can be run automatically as part of the build and integration process, and that is the topic for the next article.
-
November 29th, 2017
Mainframe Migration? Why?
This article investigates why organizations should consider Mainframe Migration, the migration options they have, and the steps they need to take to transform their mainframe workloads to run on the cloud.
Let’s set the scene a little bit for a typical large organization that runs business-critical applications on the mainframe.
- Your mainframe and your mainframe applications just run.
- It causes no heartache, no troubles; when was the last time it “went down”?
- If it weren’t for the pesky leasing payments and the endless contract renewal discussions, you probably wouldn’t give it too much thought.
But there are a few vague, uneasy feelings:
- Perhaps you are not as responsive to your customers’ requirements as you could be.
- At month-end, quarter-end, and year-end, the batch jobs are only just completed within the batch window.
- There are a lot of grey beards in the PL/1, COBOL teams
- Adding a new type of customer contract takes months with the mainframe screens and seemingly minutes with the web team.
- Let’s face it a green screen does not have the possibility to represent data that a modern web browser supports
Would you rather be working with this green screen? A COBOL/CICS application that has been deployed to Pivotal Cloud Foundry using Heirloom.
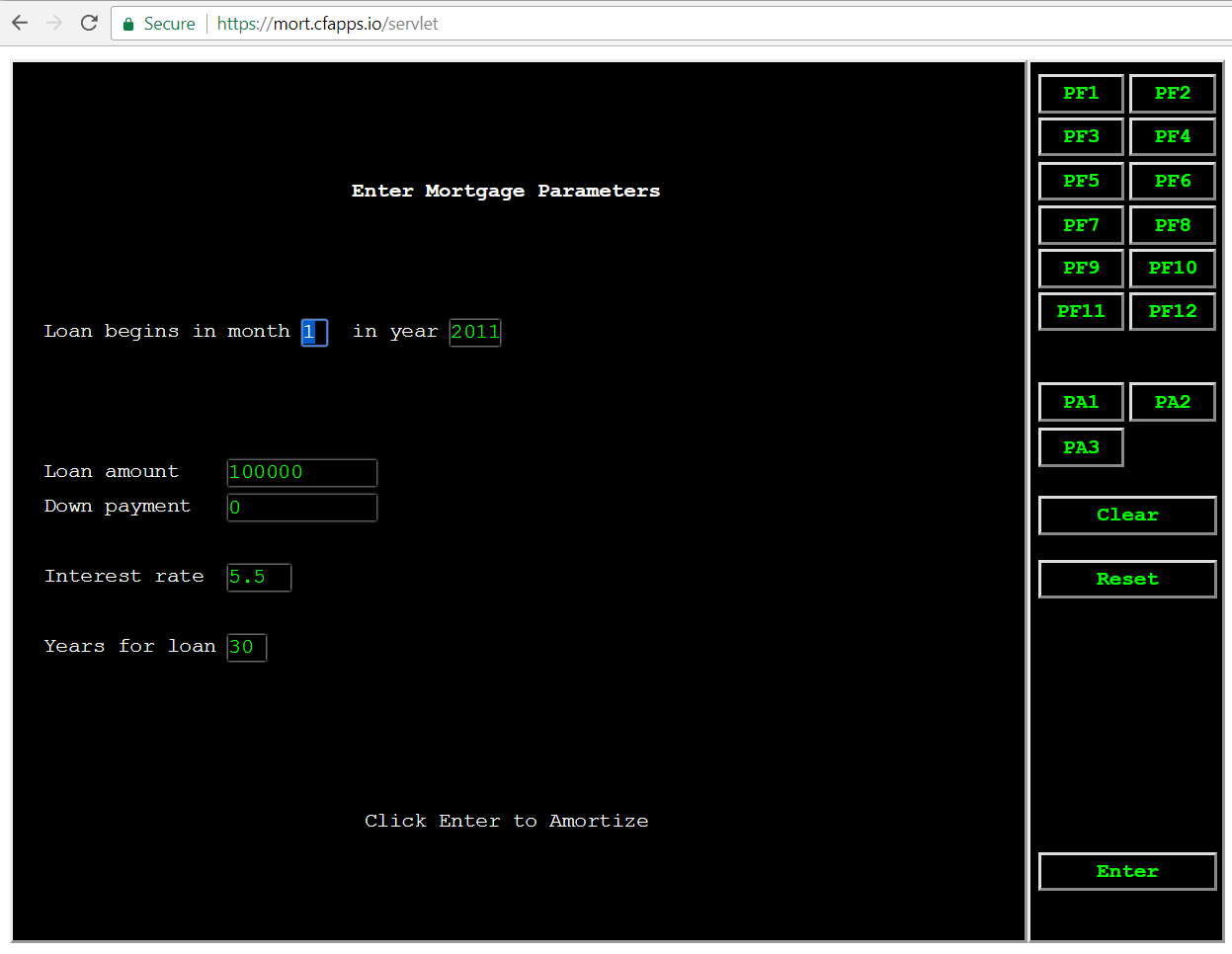
Or with this Angular and D3 application that is also running on Pivotal Cloud Foundry and using exactly the same back-end COBOL/CICS program to run the amortization calculation?

Your company’s “front-end” applications are being delivered using industry best practices, continuous integration, and continuous deployment, CI/CD of the applications is de rigueur, and perhaps most importantly, your customers are extremely happy with the features, the responsiveness, and the look and feel. These applications and the teams that create them are agile in a way that the Mainframe group is not.
At the same time, these web applications are now capable of the same reliability as your mainframe environment, not because every single component works all the time but because every component has fail-over redundancy built-in. It is a different reliability model but one to which the organization is gradually becoming accustomed.
Your company is also becoming accustomed to hardware costs for running the non-mainframe applications to actually fall each year and yet still eke out higher and higher performance. Need to have a little performance kick for black Friday? Just automatically scale out some more application instances, and pay for the extra throughput performance ONLY when it is needed.
So now the scene is set, check back here for the next post, where I will lay out various Mainframe Migration options and the pros and cons of each one.
-
August 16th, 2017
COBOL/CICS Hooks Up With Pivotal Cloud Foundry

Would you be skeptical of a claim from a vendor that stated you can take existing mainframe workloads (online and batch), and automatically transform them (with 100% accuracy) into instantly agile Java applications that can immediately be deployed to the cloud? You wouldn’t be alone. For many of our initial client meetings, there’s a palpable sense of disbelief (or healthy skepticism, if you prefer).
So, here’s another 3-minute video from Ian White, Heirloom Computing’s VP of Engineering, that demonstrates that claim, using Pivotal Cloud Foundry (PCF).
TL;DW? These are the (simplified) steps:

What happened? We took an online mainframe application and deployed it to PCF in 3 minutes. No misdirection, real code, real results, and a re-platforming project lifecycle that puts you in control (so you can avoid black-box solutions).
For us at Heirloom Computing, Cloud Foundry is a great example of how Heirloom maximizes the power of open-source stacks to provide clients with a way to include high-value mainframe workloads in strategic initiatives (e.g., cloud, digital transformation, etc.). One that protects existing functionality, but also one that is seamlessly integrated with an agile ecosystem.
-
August 9th, 2017
Amazon Alexa Hooks Up With COBOL/CICS (On The Cloud)
Gary Crook, President & CEO
There’s a lot of chatter about how to make mainframe workloads agile. I have contributed to that chatter myself. The discourse is essential. Boiled down, my assertion is that the mainframe ecosystem is foundationally not agile (and never will be). No amount of DevOps tooling or vendor misdirection is going to change that.
In my last article, I made the following statement:
Mainframe workloads are an essential part of any digital transformation strategy, but those workloads will persist in a different form. One that protects existing function, but also one that is seamlessly integrated with an agile ecosystem.
Below is a (3-minute) video that implements the above statement. It was put together inside 2 hours by Heirloom Computing’s VP of Engineering, Ian White.
This was a mainframe application that was compiled (unchanged) to Java and executed on the cloud using Heirloom, which automatically makes the workload instantly agile (all transactions are immediately accessible as a service). Agile enough for Ian to very quickly hook it up to Alexa.