Heirloom Computing Named a Leader in the ISG Provider Lens™ Mainframe Services & Solutions U.S. 2022 Quadrant Report
Posts Tagged ‘cloud-native’
-
October 3rd, 2022
Heirloom Computing Named a Leader in the ISG Provider Lens™ Mainframe Services & Solutions U.S. 2022 Quadrant Report
Heirloom® recognized as Leader for Mainframe Application Modernization Software.
Information Services Group (ISG), a well-known technology research and advisory firm renowned for its industry and technology expertise, has named Heirloom Computing a Leader in its Mainframe Services & Solutions U.S. 2022 Quadrant Report.
“Heirloom has been capturing the attention of hyperscalers and systems integrator partners with its pragmatic solution for fast mainframe migrations to the cloud. With many success cases, the company is well positioned to capture a larger market share, globally” – Pedro Luís Bicudo Maschio, Distinguished Analyst and Executive Advisor, ISG
Companies that receive the Leader award have a comprehensive product and service offering, a strong market presence, and an established competitive position. The product portfolios and competitive strategies of Leaders are strongly positioned to win business in the markets covered by the study. The Leaders also represent innovative strength and competitive stability.

Enterprises with IBM mainframes are increasingly making the decision to exit the data-center business and modernize their infrastructure to the cloud in order to increase agility and dramatically cut costs. Heirloom replatforms mainframe workloads using compiler-based refactoring to produce cloud-native applications that run on any cloud.
Highlights from the report:
“Heirloom was named a Rising Star in 2021 and is a Leader in 2022. The company continues to grow and improve its relationship with cloud providers and system integrators. It offers rapid mainframe migrations converting legacy programming languages into Java which can run on any cloud.”
“Heirloom [replatforms and] refactors mainframe workloads to cloud-native applications that can scale horizontally on AWS and other clouds. The company offers a modern refactoring toolset that attracts system integrators and cloud providers’ attention because of its code refactoring speed and scalability.”
-
January 25th, 2022
Heirloom Computing Replatforms The Avon Company’s IBM Mainframe Workloads as Cloud-Native Applications on AWS
Using Heirloom®, The Avon Company was able to decommission their IBM Mainframe
SAN FRANCISCO, Jan. 25, 2022 /PRNewswire/ — To meet its mainframe decommissioning goal, The Avon Company needed to migrate its Integrated Marketing Information System (IMIS) to Amazon Web Services (AWS). IMIS is a bespoke core IBM Mainframe application that had no alternative outside of the mainframe so the decision was made to replatform it to the cloud. To get there, The Avon Company created a technology ecosystem with Heirloom Computing and Cognizant that pivoted around AWS as the destination.
Cognizant led the project, using Heirloom Computing’s Probe™ for application inventory analysis & collection, and Heirloom® for code refactoring and data migration.
The IMIS application was replatformed into a cloud-native application running on the JVM and deployed to AWS, through a process known as automated refactoring using the Heirloom product suite.
The migration project was completed on time and underwent a parallel production period that was aligned with the mainframe decommissioning milestone.
Rick Boyle, Vice President Information Technology, The Avon Company
“The Avon Company’s decision to decommission the mainframe was driven by a business imperative to exit the data center business. At the same time, we had to ensure that the integrity of the business-critical batch processing from IMIS was retained. Heirloom Computing’s cloud-native solution delivered on all the requirements with ease.”
Gary Crook, President & CEO, Heirloom Computing
“Once again, Heirloom has clearly demonstrated that it is the fastest lowest-risk approach to replatforming and refactoring mainframe workloads to the cloud. RPA automation and compiler-based refactoring underpin Heirloom’s unique approach, producing outcomes that are guaranteed to match existing function and behavior.”
About Heirloom Computing
Heirloom Computing is an award-winning enterprise software company that partners with Global Systems Integrators and cloud providers to replatform mainframe workloads as agile cloud-native applications on any cloud. Our Global 2000 clients select us because we deliver the fastest lowest-risk transformation journey with a fully transparent process using a software platform that puts you in complete control. For more information about how Heirloom® can increase agility, and save IT departments time & money, please visit http://52.23.23.73.
Join Heirloom Computing on LinkedIn. Follow @heirloom.cc on Twitter.
Media Contact:
Glenn Boyet
328357@email4pr.com
(301) 980-0346SOURCE Heirloom Computing
-
November 17th, 2021
Heirloom Computing Showcases its Single-Click Mainframe to Cloud Software Platform
An RPA-infused integration of Heirloom® and Probe™ delivers an industry-first
SAN FRANCISCO, Nov. 17, 2021 /PRNewswire/ — In an industry-first, Heirloom Computing has achieved the remarkable feat of migrating an IBM Mainframe application to the cloud with a single click.
For organizations looking to exit the data center business and migrate to the cloud, their mainframe infrastructure represents a challenging hurdle to clear. Heirloom Computing’s compiler-based replatforming of mainframe workloads, augmented with Robotic Process Automation (RPA), translates to the fastest, lowest-risk project delivery, with an unmatched ROI.

Single-click mainframe to cloud This short video of a live session showcases how the orchestration works – it starts with a direct connection to a mainframe end-point to initiate the collection of a COBOL, CICS & VSAM application, all the way through to it executing on the AWS Elastic Beanstalk cloud platform as a Java, Apache Tomcat & RDS application.
The entire process was orchestrated from start to finish using Heirloom Computing’s inventory analysis & collection tool, Probe. As instructed by Probe, the Heirloom software platform did the heavy lifting of automatically refactoring the code for execution on the JVM and migrating the data to Amazon RDS. RPA was used to automate the entire process, migrating the application in just 2 minutes.
Pedro Maschio, Distinguished Analyst, ISG
“Heirloom Computing is a rising star in mainframe modernization software because of the outstanding speed of delivery and performance that its solutions can offer to clients. This level of automation demonstrated here takes it to the next level.”
Graham Cunningham, CTO, Heirloom Computing
“Heirloom already delivers several unique, compelling benefits, and this showcase is a clear statement that we will not stand still. We are continuing to invest heavily in applying RPA for extreme levels of automation, covering all aspects of migrating even the most complex mainframe workloads to any cloud.”
Other Resources
Read the AWS and Cognizant case studies to understand more about how Venerable achieved escape velocity and savings of over $1M per month by replatforming their mainframe workloads to the cloud. “This has been a hugely impressive implementation that has enabled Venerable to adhere to its cloud-first strategy.” – Tim Billow, CIO, Venerable.
Join Heirloom Computing on LinkedIn. Follow @heirloom.cc on Twitter.
About Heirloom Computing
Heirloom Computing is an award-winning enterprise software company that partners with Global Systems Integrators and cloud providers to replatform and refactor mainframe workloads as agile cloud-native applications on any cloud. Our Global 2000 clients select us because we deliver the fastest, lowest-risk transformation journey with a fully transparent process using a software platform that puts you in complete control. For more information about how Heirloom® and Probe™ can increase agility and dramatically cut OpEx, please visit http://52.23.23.73.
Media Contact:
Glenn Boyet
323993@email4pr.com
(301) 980-0346SOURCE Heirloom Computing
-
October 17th, 2021
Using RPA to migrate a Mainframe App to AWS Cloud in two minutes

Blurr is the fastest Autobot on the planet. We toyed (pun intended) with the idea of labeling Heirloom Computing’s use of robotic process automation (RPA) under the Blurr moniker but decided (sensibly, I think) that it would dilute our existing branding. Nonetheless, with a nod to the descendent of a Cybertronic racehorse, we’re excited to present what we believe is a stunning demonstration of how Heirloom® and Probe™ use RPA to orchestrate the entire process of taking a workload directly from an IBM Mainframe and migrating it to AWS, with one-click, in two-minutes.
So let me just spell that out – we’re going to directly connect to a mainframe end-point, and with one-click, in two-minutes we will collect the target application’s inventory, refactor the COBOL/CICS code to Java, migrate the VSAM data to an AWS RDS database, and deploy a working application to AWS Elastic Beanstalk.
Before I go on to outline how we achieved this, please watch the following 4-minute video demonstration – it’s worth it! Everything in this video is in real-time. The actual process itself, from start to finish, takes just 2m5s.

Heirloom’s core technology is compiler-based, which means it can accurately refactor (or transpile, if you prefer) millions of lines of COBOL and PL/1 code in minutes. And just like any other compiler, including the ones that run on the mainframe, you get exactly the results you coded for – no excuses. Heirloom’s Data Migration Toolkit handles the migration of mainframe datasets (such as VSAM, Sequential, DB/2 & IMS) to any JDBC compliant relational database, without needing to make any changes to the original application source code. These tasks, and many others, are scripted using the application-specific metadata extracted during inventory collection & analysis.

Does this orchestration work for every mainframe application? We’re not going to make that claim today. There are already too many other solutions in this arena that over-promise and under-deliver, even on the basic table-stakes requirement of replicating existing function & behavior.
However, our commitment to applying RPA for extreme levels of automation covering all aspects of migrating complex mainframe workloads, does define our roadmap at the highest level.
For our clients, compiler-based transformation augmented with RPA translates to the fastest lowest-risk project delivery, with an accelerated ROI.
To understand why leading companies in financial services, insurance, retail, healthcare, and government agencies, are embracing Heirloom, read how Venerable achieved escape velocity and saved $1M every month when replatforming their mainframe workloads as agile cloud-native Java applications on AWS, or how mainframe applications can scale horizontally with outstanding performance on highly-available cloud infrastructures like AWS Elastic Beanstalk.
-
May 13th, 2021
Heirloom Computing Named a Rising Star in ISG Provider Lens™ Mainframe Services & Solutions U.S. 2021 Report
Heirloom® recognized as Rising Star for Mainframe Modernization Software
SAN FRANCISCO, May 13, 2021 /PRNewswire/ — Information Services Group (ISG), a leading global technology research and advisory firm, known for its industry and technology expertise, has named Heirloom Computing a Rising Star in its ISG Provider Lens™ Mainframe Services & Solutions U.S. 2021 Quadrant Report. In response to customer demand, ISG evaluated 47 vendors and service providers in five quadrants.

As detailed in the report, companies designated as a Rising Star have excellent management and understanding of the local market. This designation is only given to vendors or service providers that have made significant progress toward their goals in the last 12 months and are expected to reach the Leader quadrant within the next 12 to 24 months due to their above-average impact and strength for innovation.
The report recognized Heirloom Computing for:
- Migration speed and scale.
- Database transformation.
- Coexistence of programming platforms.
Jan Erik Aase, Partner and Global Leader, ISG Provider Lens Research.
“The mainframe modernization market has been accelerating in the last two years, driven by the need of organizations to increase agility and lower operating costs.”
Pedro Luís Bicudo Maschio, Lead Analyst & Author, ISG Provider Lens Research
“Heirloom refactors mainframe applications to cloud-native Java programs that can scale horizontally on AWS and other clouds. The company offers a modern refactoring toolset that attracts system integrators and cloud providers’ attention because of its code refactoring speed and scalability.”
Gary Crook, President & CEO, Heirloom Computing
“We’re exceptionally proud to have Heirloom recognized in this way. As the only cloud-native replatforming solution in the market, we remain committed to innovation that drives automation and value into every phase of the replatforming process to ensure risks are minimized and ROI is maximized.”
Additional Resources
- Join Heirloom Computing on LinkedIn.
- Follow @heirloom.cc on Twitter.
- Read a recent case study from the financial services industry.
About Heirloom Computing
Heirloom Computing is an enterprise software company that partners with Global Systems Integrators and cloud providers to replatform mainframe workloads as agile cloud-native Java applications on any cloud. Our Global 2000 clients select us because we deliver the fastest lowest-risk transformation journey with a fully transparent process using a software platform that puts you in complete control. For more information about how Heirloom® can increase agility, and save IT departments time & money, please visit http://52.23.23.73.
About ISG Provider Lens™ Research
The ISG Provider Lens™ Quadrant research series is the only service provider evaluation of its kind to combine empirical, data-driven research and market analysis with the real-world experience and observations of ISG’s global advisory team. Enterprises will find a wealth of detailed data and market analysis to help guide their selection of appropriate sourcing partners, while ISG advisors use the reports to validate their own market knowledge and make recommendations to ISG’s enterprise clients. The research currently covers providers offering their services globally, across Europe, as well as in the U.S., Germany, Switzerland, the U.K., France, the Nordics, Brazil and Australia/New Zealand, with additional markets to be added in the future. For more information about ISG Provider Lens research, please visit this webpage.
Media Contact:
Glenn Boyet
309498@email4pr.com
(301) 980-0346SOURCE Heirloom Computing
-
May 11th, 2021
Heirloom Computing Named a Leader in the ISG Provider Lens™ Mainframe Services & Solutions U.S. 2021 Quadrant Report
Heirloom® recognized as Rising Star for Mainframe Modernization Software.
Information Services Group (ISG), a well-known technology research and advisory firm renowned for its industry and technology expertise, has named Heirloom Computing a Leader in its Mainframe Services & Solutions U.S. 2021 Quadrant Report.
Companies that receive the Rising Star award have a promising portfolio or the market experience to become a leader, including the required roadmap and adequate focus on key market trends and customer requirements. Rising Stars also have excellent management and understanding of the local market. This award is only given to vendors or service providers that have made significant progress toward their goals in the last 12 months and are expected to reach the Leader quadrant within the next 12 to 24 months due to their above-average impact and strength for innovation.

Enterprises with IBM mainframes are increasingly making the decision to exit the data-center business and modernize their infrastructure to the cloud in order to increase agility and dramatically cut costs. Heirloom replatforms mainframe workloads using compiler-based refactoring to produce cloud-native Java applications that run on any cloud.
“Heirloom toolset delivers fast and effective refactoring for large-scale mainframe modernizations and migrations to the cloud.”
“Heirloom refactors mainframe applications to cloud-native Java programs that can scale horizontally on AWS and other clouds. The company offers a modern refactoring toolset that attracts system integrators and cloud providers’ attention because of its code refactoring speed and scalability.”
-
January 1st, 2021
Execute a refactored IBM Mainframe Application on Multiple Clouds with Heirloom®


Heirloom replatforms and refactors online & batch mainframe workloads at compiler speed to cloud-native Java applications. During refactoring, it automatically makes those applications agile by exposing the primary business rules as RESTful web services.

We migrated a sample Mainframe “Account” application, packaged it as a standard Java war file, and deployed it to Alibaba Cloud, Amazon AWS Beanstalk, Google App Engine, IBM Cloud Foundry, and Microsoft Azure Web App (the links will take you to the application’s landing page). The war file is exactly the same package for all 5 cloud environments, ensuring you can retain the option to deploy to your preferred cloud(s).
When clicking on any of the application links above, bear in mind the initial response time may well be a tad sluggish. This is because:
The applications are running on virtualized micro instances (the smallest possible).
The instance count in each cloud is limited to 1.
The applications are deployed across the globe (various US locations and China).
All applications are accessing the same database (a Google SQL instance hosted on the US West Coast).
The database is also running on the smallest possible instance (it’s also read-only, so any attempts to update the database will result in the application telling you the update failed).
You’re reading this article a month (or so) after the publication date (i.e. some/all of the instances have been temporarily suspended).

These environments are artificially constrained. With the constraints lifted, every cloud platform used can seamlessly scale on-demand, with instances distributed across multiple geographies and availability zones (for high-availability), along with centralized management & monitoring. If you wanted to be a little more adventurous you could even set up a load-balancer and distribute your end-users across all 5 cloud applications!
Refactoring to industry-standard Java packages means Heirloom applications can immediately exploit the native capabilities of the target cloud platform.
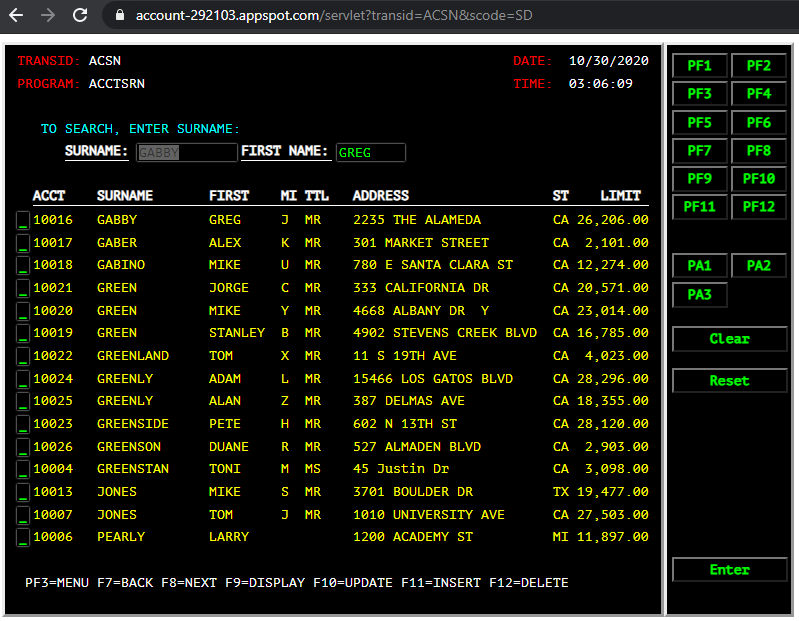
When you access the application’s landing page, you will see 2 options. The first link is the default UI which emulates the function & behavior of the original 3270 screens. You will be taken to this UI after 10 seconds (if you don’t select the other option).
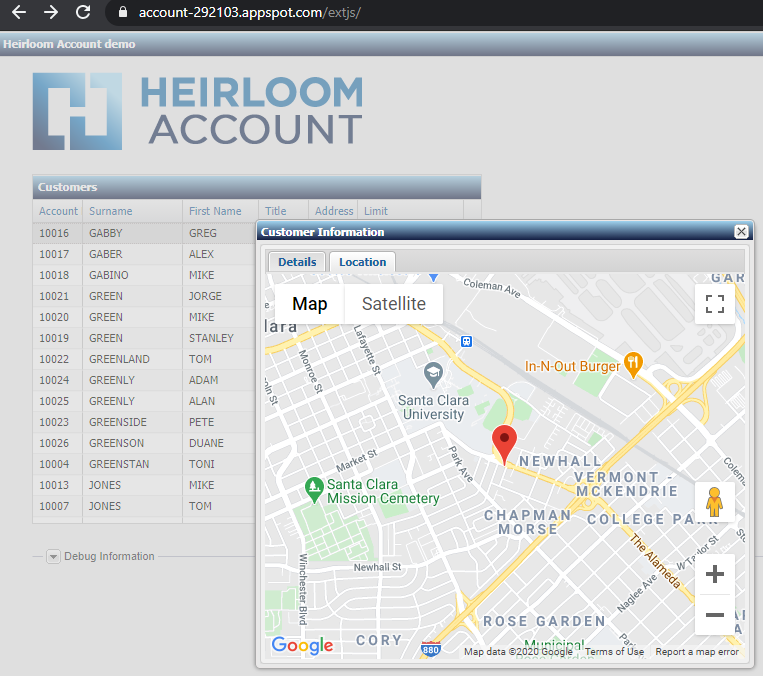
The second link is a JavaScript UI (created using the Ext JS framework). This is an example of how to quickly modernize the UI by interfacing directly to the CICS transactions that were automatically exposed as RESTful web services during refactoring. Once you’ve clicked “Load”, you will be presented with a sortable table. Double-clicking on a record will interface to Google Maps to locate the address. This particular UI was built in less than an hour, with no underlying changes necessary to the original application.
These instances are no longer running. Please contact us for a demo.
Amazon AWS Beanstalk, default UI, http://heirloomaccountenv.eba-yvfsrrm4.us-east-1.elasticbeanstalk.com/servlet
Amazon AWS Beanstalk, JavaScript UI, http://heirloomaccountenv.eba-yvfsrrm4.us-east-1.elasticbeanstalk.com/extjs/
Alibaba Cloud, default UI, http://8.210.99.190/servlet
Alibaba Cloud, JavaScript UI, http://8.210.99.190/extjs
Google App Engine, default UI, https://account-292103.appspot.com/servlet
Google App Engine, JavaScript UI, https://account-292103.appspot.com/extjs
IBM Cloud Foundry, default UI, https://account-us-south.mybluemix.net/servlet
IBM Cloud Foundry, JavaScript UI, https://account-us-south.mybluemix.net/extjs
Microsoft Azure Web App, default UI, https://heirloomacct.azurewebsites.net/servlet
Microsoft Azure Web App, JavaScript UI, https://heirloomacct.azurewebsites.net/extjs
-
December 12th, 2020
Heirloom Transforms Custom Mainframe CRM App to On-Premise Cloud in 90 Days
FREMONT, Calif.–(BUSINESS WIRE)–Heirloom Computing today announced that OCLC has utilized Heirloom® to enhance IT agility by transforming a mission-critical mainframe workload to a cost-effective, open-systems platform.
When OCLC needed to enhance IT agility, they discovered that Heirloom PaaS was aligned with their need to modernize their application portfolio and move away from their dependence on an inflexible and expensive IBM mainframe infrastructure.
“Heirloom’s platform and outstanding project team delivered on the promise of automatically transforming and deploying a complex mainframe workload to the JVM in 90 days,” said Tim Schwab, Director of Enterprise Applications at OCLC.
Kevin Moultrup, Heirloom’s COO, said “With automatic transformation of mainframe workloads and guaranteed preservation of existing business logic, Heirloom enables any company with an expensive legacy infrastructure, to move with great speed to a Java platform that is cloud-enabled.”
About Heirloom Computing
Heirloom Computing is an enterprise software company that partners with Global Systems Integrators and cloud providers to replatform mainframe workloads as agile cloud-native applications on any cloud. Our Global 2000 clients select us because we deliver the fastest lowest-risk transformation journey with a fully transparent process using a software platform that puts you in complete control. For more information about how Heirloom® can increase agility, and save IT departments time & money, please visit https://heirloomcomputing.com.
About OCLC
OCLC is a global library cooperative that provides shared technology services, original research, and community programs for its membership and the library community at large. We are librarians, technologists, researchers, pioneers, leaders, and learners. With thousands of library members in more than 100 countries, we come together as OCLC to make information more accessible and more useful.
SOURCE Heirloom Computing
-
October 1st, 2020
How Heirloom® automatically refactors Mainframe workloads as cloud-native applications on Alibaba Cloud

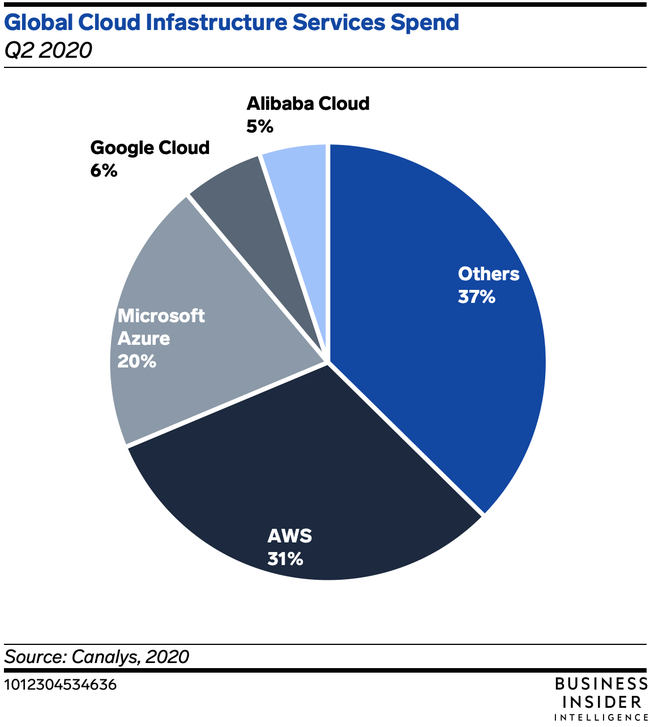
I think most readers have some awareness of the Alibaba brand, but perhaps a somewhat more obscure understanding of the scope of this $850B Chinese multinational powerhouse. Most of us in high-tech work with cloud platforms from Amazon, Google, IBM, and Microsoft. Alibaba also has a thriving cloud platform, with Q2 2020 revenue increasing 59% YoY to $1.7B.
I have already posted articles on how easily Heirloom refactors mainframe workloads to Pivotal Cloud Foundry, AWS, Google App Engine, and the IBM Cloud.
Heirloom applications already run natively on multiple clouds. So what about Alibaba’s Cloud? It was very easy!
Here’s a summary of the required steps which took less than an hour to complete (prerequisites: an Heirloom Account and an Alibaba Cloud Account).
Recompiling the COBOL/CICS application into a Java .war package
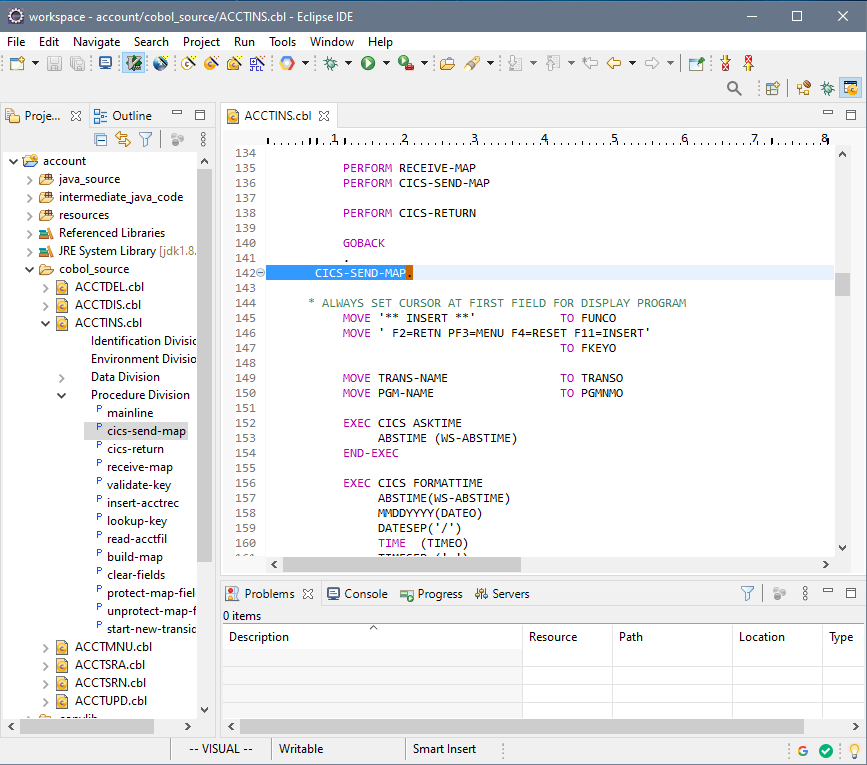
STEP 1: Recompile. Create a new project in the Heirloom SDK using the built-in “account” application. As soon as the project is created, it will automatically be compiled into 100% Java (this literally takes just a few seconds), ready for deployment to any industry-standard light-weight Java Application Server (such as Apache Tomcat, which is the one utilized by Alibaba’s Web App Service).
Heirloom automatically replatforms & refactors Mainframe online & batch workloads to cloud-native applications.
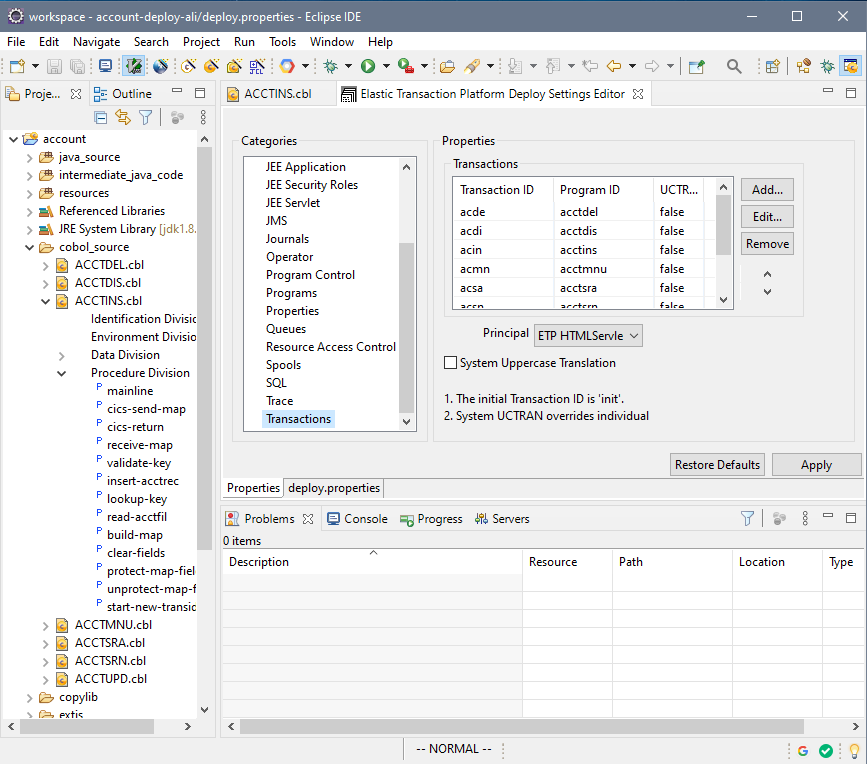
STEP 2: Configure the deployment project. This is where we set up deployment information that tells the application things like how transactions IDs relate to programs and the end-point for the database (we are going to use an Alibaba ApsaraDB RDS for PostgreSQL instance).
Mainframe datasets are migrated to relational database tables.
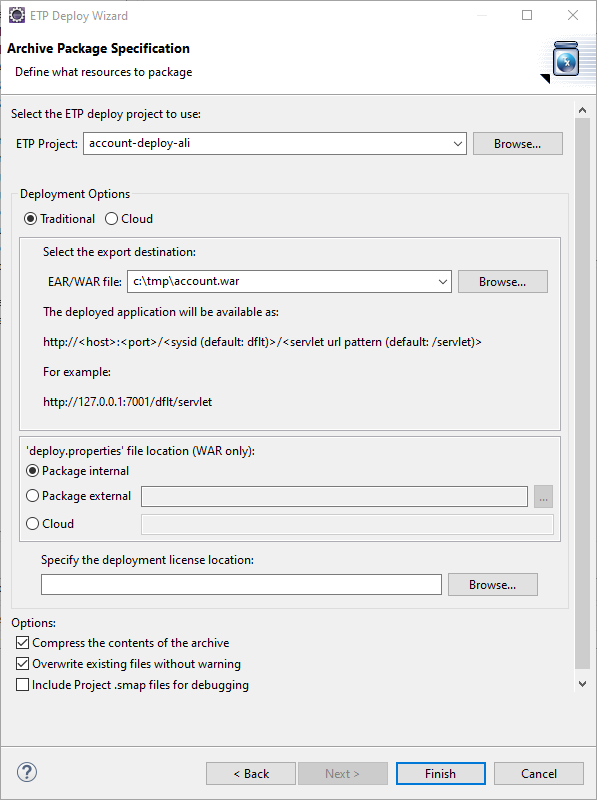
STEP 3: Package the application as a Java .war file. This is done using Heirloom’s built-in “Export Wizard” (again, this literally takes just a few seconds). We now have an “account.war” package that contains everything we need to execute the application in exactly the same way as it used to run on the Mainframe. Only now, it has been refactored to a cloud-native Java application that we can deploy to any managed or serverless cloud we want.
Heirloom applications are standard Java packages, which means they immediately leverage native cloud services such as dynamic scaling, high-availability and centralized management.
Setup, Deploy & Execute Application on the Alibaba Cloud
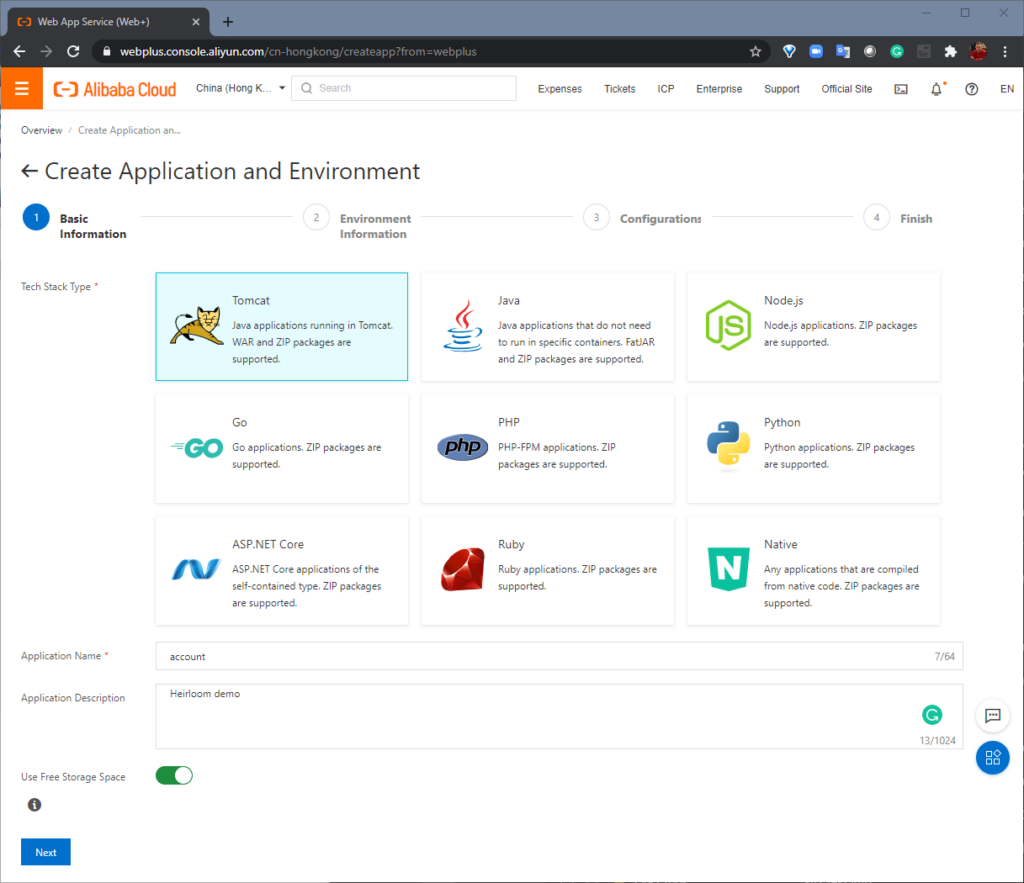
STEP 1: Setup. From the Alibaba Cloud Console, “Basic Information” is where we create a “Web App Service” using Apache Tomcat. Next, “Environment Information” is where we choose our specific Tomcat stack and upload the “account.war” package that we built with Heirloom. Alibaba Cloud will then create the environment (this takes just a few minutes).
Unlike rehosting solutions which need vendor-proprietary application servers, Heirloom applications deploy to open industry-standard Java Application Servers.
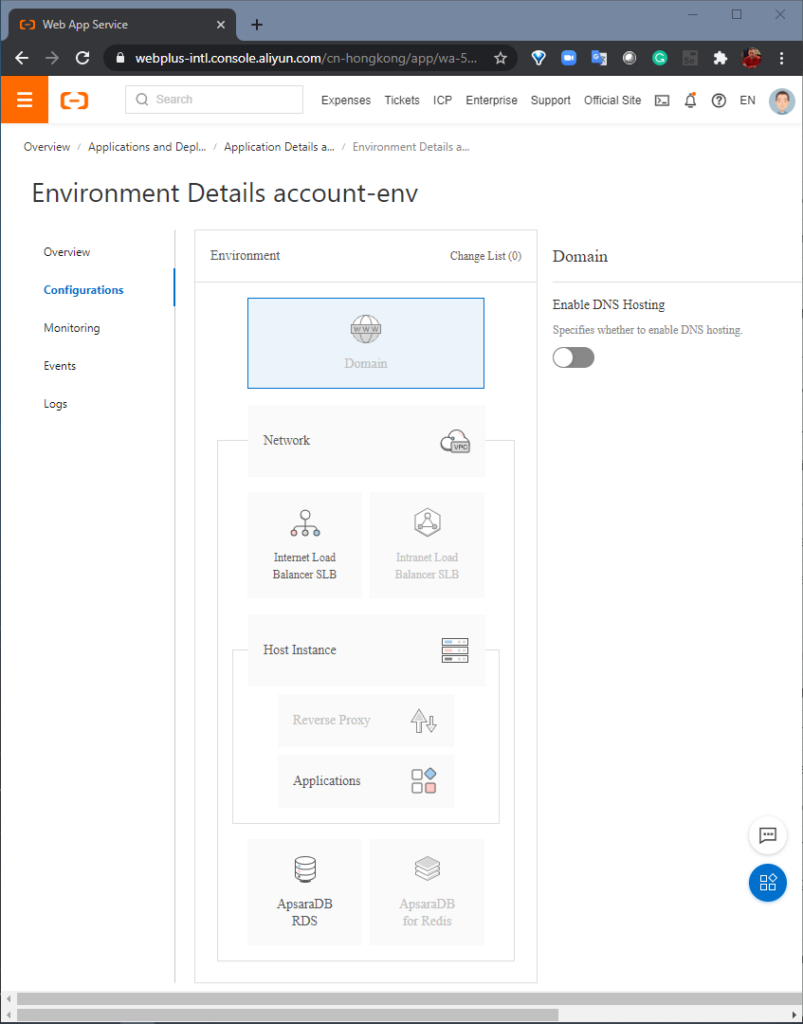
STEP 2: Configure. Here, we add an “Internet Load Balancer”, which will allow multiple client connections to the application to retain persistent sessions to multiple instances. Next, we create an “AsparaDB RDS” database, which is populated by a powerful data migration toolkit (included in the Heirloom SDK) that migrates mainframe datasets (VSAM, sequential, relational) to relational tables in the target database. The data transparency layer within the Heirloom Framework means that this can be done without needing to change the original application source code.
Configuration of the application environment is done natively within the cloud platform, and independently of the refactored Heirloom application.
STEP 3: Execute. Out of the box, this particular application has 2 user interfaces that are both accessed via a standard browser.
The first is the existing 3270-style interface that will function and behave exactly as it did on the mainframe. There is no additional application code required here. Just the original application artifacts, such as COBOL source, data, BMS maps, etc.
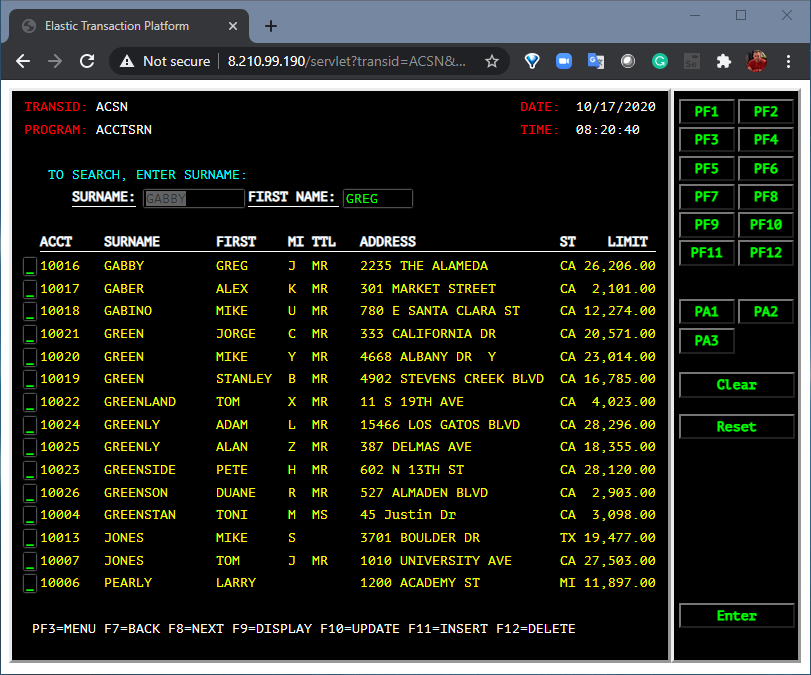
Heirloom applications are guaranteed to match existing function & behavior of the mainframe workload.
The second uses an additional application written in a Javascript UI framework called Ext JS (you can use others such as Angular, React, JQuery, etc.). What’s happening here is that the modernized UI (i.e. the Ext JS application) is interacting directly with the CICS transactions that have been automatically exposed via REST (this happens by default when refactoring with Heirloom). The application itself has not changed. It is still processing CICS transactions, but in such a way that they are now aggregated by the Ext JS application which renders them into a sortable table. Additionally, the new UI then uses the data to extend the functionality of the application (in this case, showing the address location of a particular customer using Google Maps).
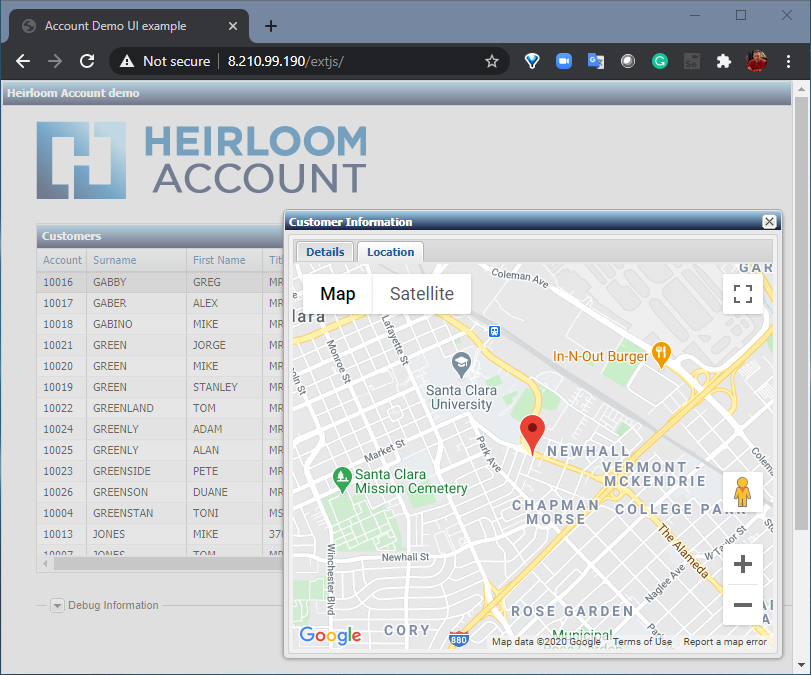
Not only is Heirloom the fastest most cost-effective way to refactor mainframe workloads to the cloud, they are instantly agile. UI modernization is just one possibility; others include breaking the monolith into microservices.
-
September 1st, 2020
Mainframe to the Cloud, the Right Way (Avoiding Gilded Cages)


The Elephant In The Room
After decades of evolution within a constrained ecosystem, mainframe applications are prodigiously complex & inflexible. And it’s not just the code … it’s the data, it’s the operational processes, it’s the security rules, it’s all the interfaces … in many variations and multiple combinations. Until recently, when cloud strategies were fervently discussed inside the rooms of Financial Services companies, Government departments, and elsewhere, the mainframe was the elephant in the room. Today, the progressive CIO has embraced the cloud and has sat the elephant at the table. So, what is the right approach that delivers the most value?

Reengineering?
Nope.
Look, I get the appeal. The idea that you can analyze a complex monolith to accurately extract business rules into an abstract model from which you can generate a brand-new shiny application with zero technical debt, is compelling. Having just written that sentence, I’m excited!
The problem is it just doesn’t work out that way. You will spend years paying your Systems Integrator to manually remediate low-fidelity generated code and write extensive test frameworks just to make it function as before. Then, if you survive, you are left with an entirely new application architecture that was imposed on you by your weapon of choice (MVC, anyone?) and a bunch of bespoke code written by a team who doesn’t even work for you. Guess what? That is technical debt — not only is it a prescriptive model rather than one aligned with your end-state, but it is also one that is less well understood than what you started with.
Let’s call it what it is:
Reengineering is a low-fidelity tools-based approach to rewriting an application that forces you to adopt an end-state that is not cloud-native and one in which you had no say in determining.

Rehosting/Emulation?
Nope.
I’ve been there, done that (prior company). More commonly known as “Lift & Shift”. With this approach, you are basically swapping the hardware. That’s it.
At the application layer, you are still dependent upon a vendor’s proprietary application server (just like you were before). You are still locked-in to the host language (predominantly COBOL, or perhaps PL/I or Natural — just like you were before). You are still entrenched in a scale-up application architecture that was first delivered by IBM in 1964 (just like you were before).
Let’s call it what it is:
Rehosting is an emulation-based approach that delivers no strategic value, locks you in to your technical debt, and forces you to adopt an end-state that is not cloud-native.

Replatforming?
Yep.
If you click on the rocket image to the right, you’ll see a 30-second video from Pivotal that does a great job explaining what replatforming is. This approach is also described as “automatic refactoring” by some.
At the core is a compiler that quickly and accurately recompiles online & batch mainframe applications (written in COBOL, PL/I, Natural) into 100% Java. Literally, compiling millions of lines-of-code in minutes, with guaranteed accuracy (just as you would expect from any compiler).
Refactored applications execute under any industry-standard Java Application Server (e.g. Apache Tomcat, Eclipse Jetty, Wildfly).
If you’re targeting the cloud and not deploying to a Java Application Server, you need to rethink your approach!
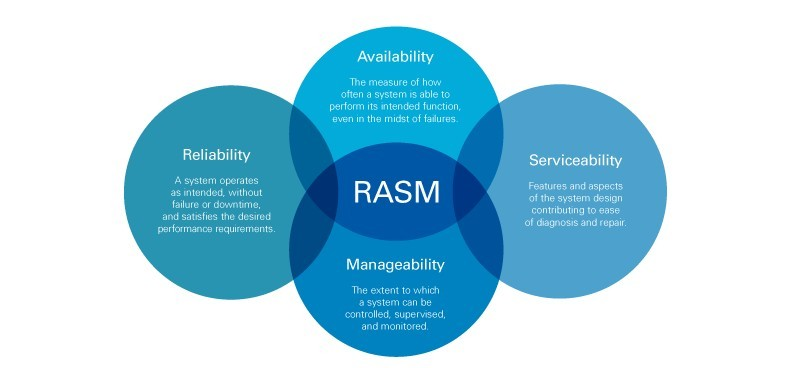
Executing under a Java Application Server means your application can be quickly & seamlessly integrated into your cloud-native platform of choice (including serverless environments). Which means it will scale horizontally on-demand, with high-availability (across multiple regions & zones), and with serviceability via centralized management & monitoring. Cloud-native Java applications deliver RAS(M).
Let’s call it what it is:
Replatforming is a fast & accurate compiler-based approach that delivers strategic value through creation of modern agile applications using an open industry-standard deployment model that is cloud-native.
Summary
Let’s say you’re attempting to make a road trip from Chicago to New York:
Reengineering will take you through the scenic route. You’ll never find a multi-lane roadway, and it’s likely you’ll visit all 50 states (yes, including Hawaii). When you arrive in Washington DC your vendor will tell you it’s been the trip of a lifetime.
Rehosting will put you on a highway/motorway but in the wrong direction, and you’ll end up in Milwaukee (the closest major city to Chicago). Your vendor will tell you that Milwaukee is the new New York.
Replatforming puts you on the fastest most-accurate route to New York. Once there, your vendor will ask you, where next? Large-scale cloud deployment? Smart-device integration? Breaking the monolith (into microservices)?