Heirloom Computing Named a Leader in the ISG Provider Lens™ Mainframe Services & Solutions U.S. 2021 Quadrant Report
Posts Tagged ‘mainframe migration’
-
May 11th, 2021
Heirloom Computing Named a Leader in the ISG Provider Lens™ Mainframe Services & Solutions U.S. 2021 Quadrant Report
Heirloom® recognized as Rising Star for Mainframe Modernization Software.
Information Services Group (ISG), a well-known technology research and advisory firm renowned for its industry and technology expertise, has named Heirloom Computing a Leader in its Mainframe Services & Solutions U.S. 2021 Quadrant Report.
Companies that receive the Rising Star award have a promising portfolio or the market experience to become a leader, including the required roadmap and adequate focus on key market trends and customer requirements. Rising Stars also have excellent management and understanding of the local market. This award is only given to vendors or service providers that have made significant progress toward their goals in the last 12 months and are expected to reach the Leader quadrant within the next 12 to 24 months due to their above-average impact and strength for innovation.

Enterprises with IBM mainframes are increasingly making the decision to exit the data-center business and modernize their infrastructure to the cloud in order to increase agility and dramatically cut costs. Heirloom replatforms mainframe workloads using compiler-based refactoring to produce cloud-native Java applications that run on any cloud.
“Heirloom toolset delivers fast and effective refactoring for large-scale mainframe modernizations and migrations to the cloud.”
“Heirloom refactors mainframe applications to cloud-native Java programs that can scale horizontally on AWS and other clouds. The company offers a modern refactoring toolset that attracts system integrators and cloud providers’ attention because of its code refactoring speed and scalability.”
-
January 1st, 2021
Execute a refactored IBM Mainframe Application on Multiple Clouds with Heirloom®


Heirloom replatforms and refactors online & batch mainframe workloads at compiler speed to cloud-native Java applications. During refactoring, it automatically makes those applications agile by exposing the primary business rules as RESTful web services.

We migrated a sample Mainframe “Account” application, packaged it as a standard Java war file, and deployed it to Alibaba Cloud, Amazon AWS Beanstalk, Google App Engine, IBM Cloud Foundry, and Microsoft Azure Web App (the links will take you to the application’s landing page). The war file is exactly the same package for all 5 cloud environments, ensuring you can retain the option to deploy to your preferred cloud(s).
When clicking on any of the application links above, bear in mind the initial response time may well be a tad sluggish. This is because:
The applications are running on virtualized micro instances (the smallest possible).
The instance count in each cloud is limited to 1.
The applications are deployed across the globe (various US locations and China).
All applications are accessing the same database (a Google SQL instance hosted on the US West Coast).
The database is also running on the smallest possible instance (it’s also read-only, so any attempts to update the database will result in the application telling you the update failed).
You’re reading this article a month (or so) after the publication date (i.e. some/all of the instances have been temporarily suspended).

These environments are artificially constrained. With the constraints lifted, every cloud platform used can seamlessly scale on-demand, with instances distributed across multiple geographies and availability zones (for high-availability), along with centralized management & monitoring. If you wanted to be a little more adventurous you could even set up a load-balancer and distribute your end-users across all 5 cloud applications!
Refactoring to industry-standard Java packages means Heirloom applications can immediately exploit the native capabilities of the target cloud platform.
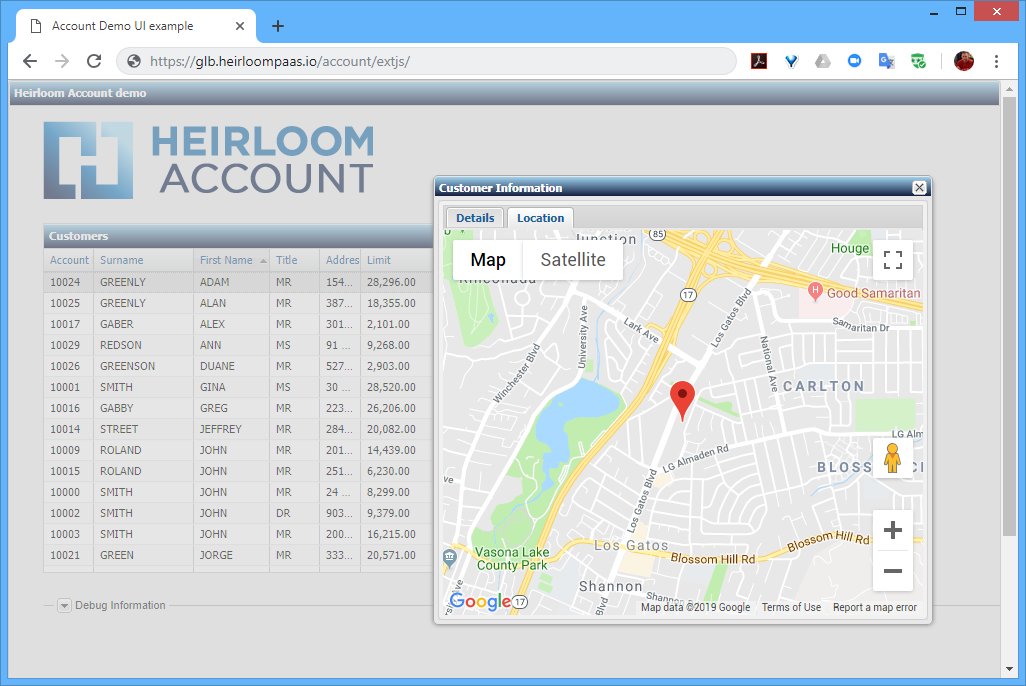
When you access the application’s landing page, you will see 2 options. The first link is the default UI which emulates the function & behavior of the original 3270 screens. You will be taken to this UI after 10 seconds (if you don’t select the other option).
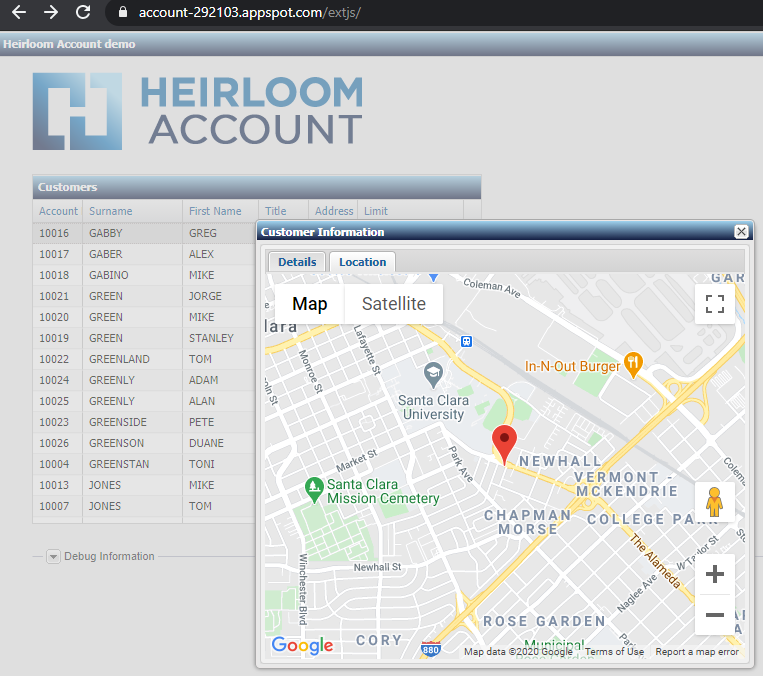
The second link is a JavaScript UI (created using the Ext JS framework). This is an example of how to quickly modernize the UI by interfacing directly to the CICS transactions that were automatically exposed as RESTful web services during refactoring. Once you’ve clicked “Load”, you will be presented with a sortable table. Double-clicking on a record will interface to Google Maps to locate the address. This particular UI was built in less than an hour, with no underlying changes necessary to the original application.
These instances are no longer running. Please contact us for a demo.
Amazon AWS Beanstalk, default UI, http://heirloomaccountenv.eba-yvfsrrm4.us-east-1.elasticbeanstalk.com/servlet
Amazon AWS Beanstalk, JavaScript UI, http://heirloomaccountenv.eba-yvfsrrm4.us-east-1.elasticbeanstalk.com/extjs/
Alibaba Cloud, default UI, http://8.210.99.190/servlet
Alibaba Cloud, JavaScript UI, http://8.210.99.190/extjs
Google App Engine, default UI, https://account-292103.appspot.com/servlet
Google App Engine, JavaScript UI, https://account-292103.appspot.com/extjs
IBM Cloud Foundry, default UI, https://account-us-south.mybluemix.net/servlet
IBM Cloud Foundry, JavaScript UI, https://account-us-south.mybluemix.net/extjs
Microsoft Azure Web App, default UI, https://heirloomacct.azurewebsites.net/servlet
Microsoft Azure Web App, JavaScript UI, https://heirloomacct.azurewebsites.net/extjs
-
December 12th, 2020
Heirloom Transforms Custom Mainframe CRM App to On-Premise Cloud in 90 Days
FREMONT, Calif.–(BUSINESS WIRE)–Heirloom Computing today announced that OCLC has utilized Heirloom® to enhance IT agility by transforming a mission-critical mainframe workload to a cost-effective, open-systems platform.
When OCLC needed to enhance IT agility, they discovered that Heirloom PaaS was aligned with their need to modernize their application portfolio and move away from their dependence on an inflexible and expensive IBM mainframe infrastructure.
“Heirloom’s platform and outstanding project team delivered on the promise of automatically transforming and deploying a complex mainframe workload to the JVM in 90 days,” said Tim Schwab, Director of Enterprise Applications at OCLC.
Kevin Moultrup, Heirloom’s COO, said “With automatic transformation of mainframe workloads and guaranteed preservation of existing business logic, Heirloom enables any company with an expensive legacy infrastructure, to move with great speed to a Java platform that is cloud-enabled.”
About Heirloom Computing
Heirloom Computing is an enterprise software company that partners with Global Systems Integrators and cloud providers to replatform mainframe workloads as agile cloud-native applications on any cloud. Our Global 2000 clients select us because we deliver the fastest lowest-risk transformation journey with a fully transparent process using a software platform that puts you in complete control. For more information about how Heirloom® can increase agility, and save IT departments time & money, please visit http://52.23.23.73.
About OCLC
OCLC is a global library cooperative that provides shared technology services, original research, and community programs for its membership and the library community at large. We are librarians, technologists, researchers, pioneers, leaders, and learners. With thousands of library members in more than 100 countries, we come together as OCLC to make information more accessible and more useful.
SOURCE Heirloom Computing
-
October 1st, 2020
How Heirloom® automatically refactors Mainframe workloads as cloud-native applications on Alibaba Cloud

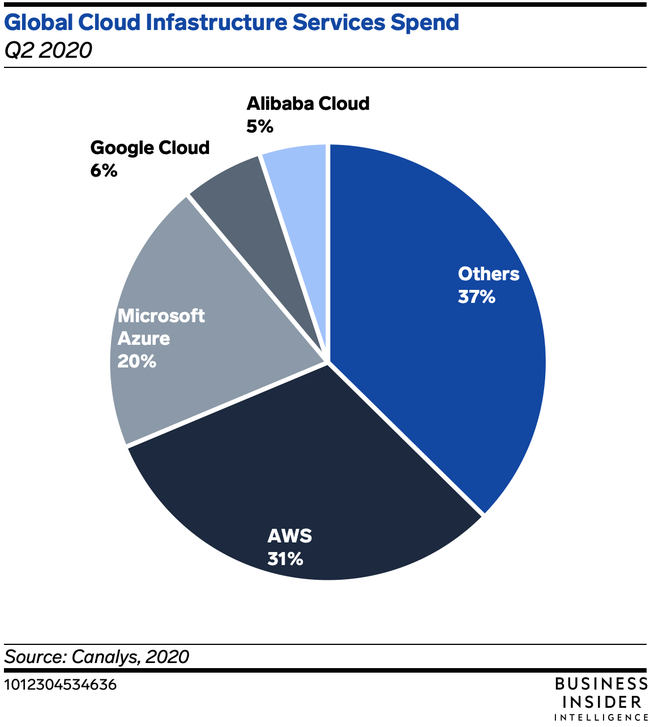
I think most readers have some awareness of the Alibaba brand, but perhaps a somewhat more obscure understanding of the scope of this $850B Chinese multinational powerhouse. Most of us in high-tech work with cloud platforms from Amazon, Google, IBM, and Microsoft. Alibaba also has a thriving cloud platform, with Q2 2020 revenue increasing 59% YoY to $1.7B.
I have already posted articles on how easily Heirloom refactors mainframe workloads to Pivotal Cloud Foundry, AWS, Google App Engine, and the IBM Cloud.
Heirloom applications already run natively on multiple clouds. So what about Alibaba’s Cloud? It was very easy!
Here’s a summary of the required steps which took less than an hour to complete (prerequisites: an Heirloom Account and an Alibaba Cloud Account).
Recompiling the COBOL/CICS application into a Java .war package
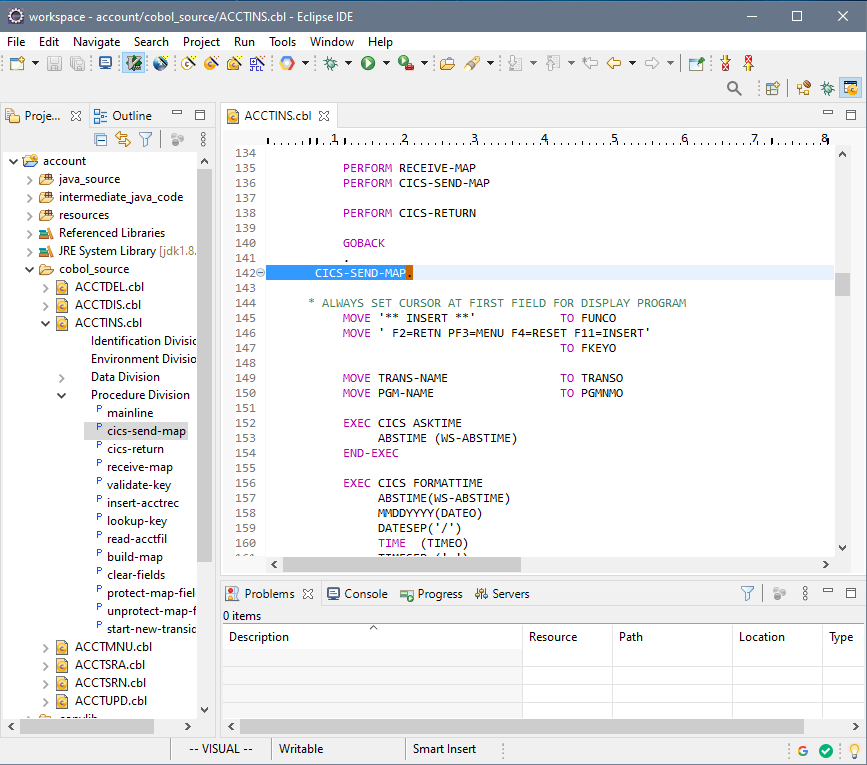
STEP 1: Recompile. Create a new project in the Heirloom SDK using the built-in “account” application. As soon as the project is created, it will automatically be compiled into 100% Java (this literally takes just a few seconds), ready for deployment to any industry-standard light-weight Java Application Server (such as Apache Tomcat, which is the one utilized by Alibaba’s Web App Service).
Heirloom automatically replatforms & refactors Mainframe online & batch workloads to cloud-native applications.
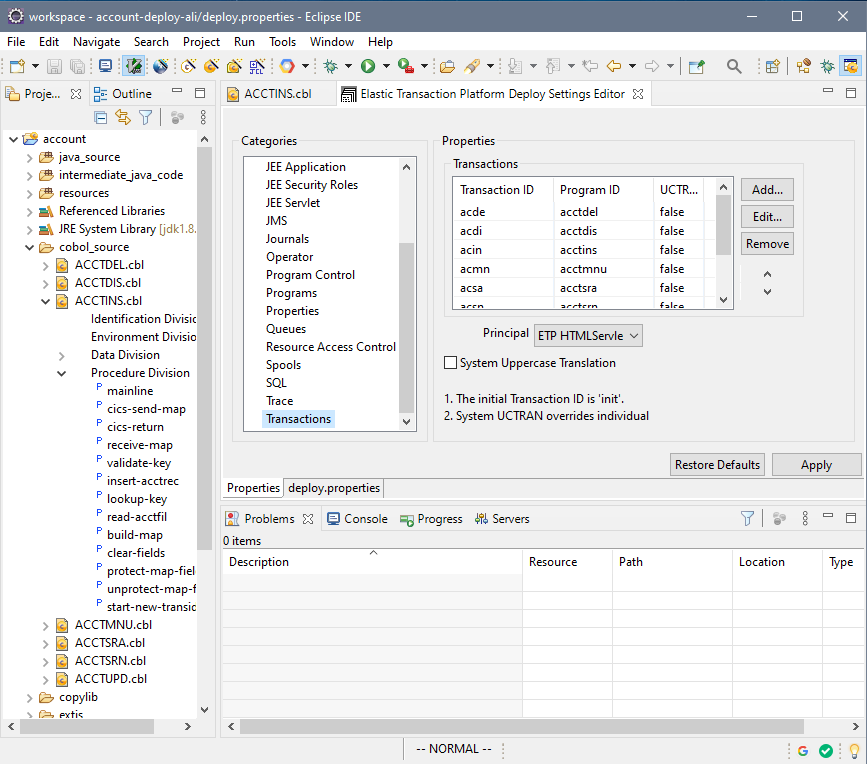
STEP 2: Configure the deployment project. This is where we set up deployment information that tells the application things like how transactions IDs relate to programs and the end-point for the database (we are going to use an Alibaba ApsaraDB RDS for PostgreSQL instance).
Mainframe datasets are migrated to relational database tables.
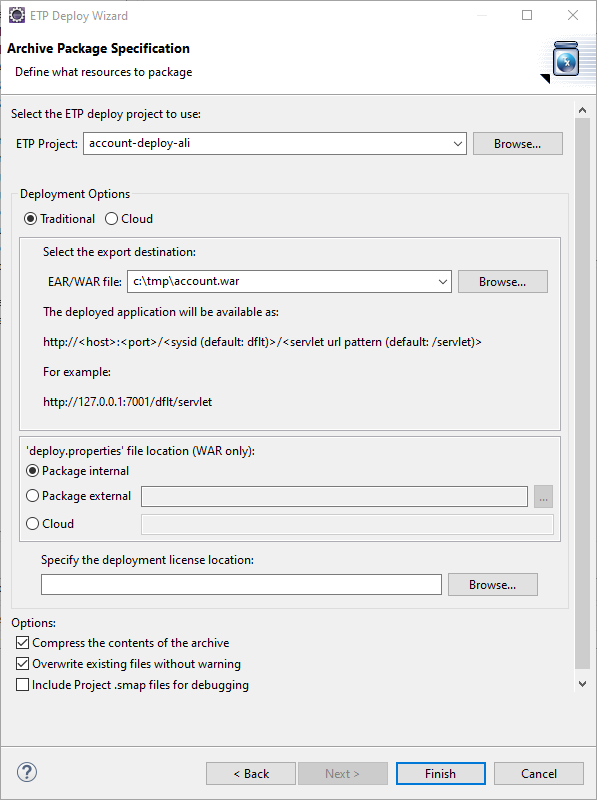
STEP 3: Package the application as a Java .war file. This is done using Heirloom’s built-in “Export Wizard” (again, this literally takes just a few seconds). We now have an “account.war” package that contains everything we need to execute the application in exactly the same way as it used to run on the Mainframe. Only now, it has been refactored to a cloud-native Java application that we can deploy to any managed or serverless cloud we want.
Heirloom applications are standard Java packages, which means they immediately leverage native cloud services such as dynamic scaling, high-availability and centralized management.
Setup, Deploy & Execute Application on the Alibaba Cloud
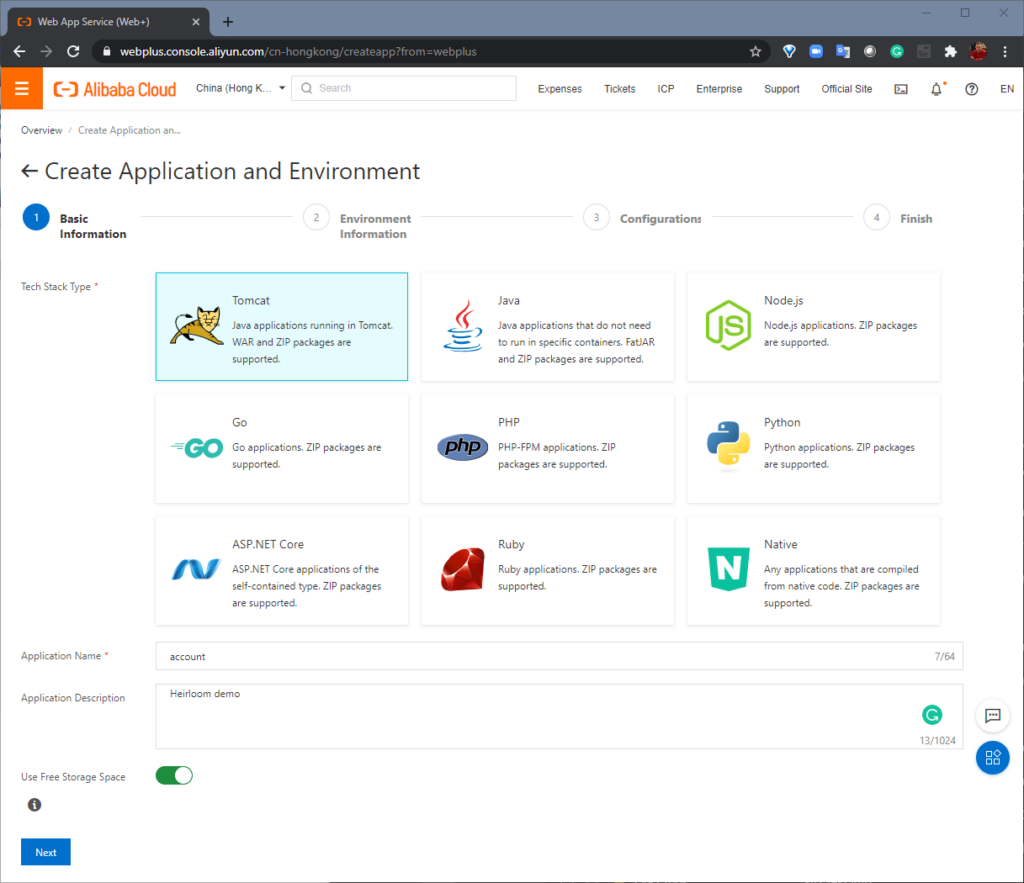
STEP 1: Setup. From the Alibaba Cloud Console, “Basic Information” is where we create a “Web App Service” using Apache Tomcat. Next, “Environment Information” is where we choose our specific Tomcat stack and upload the “account.war” package that we built with Heirloom. Alibaba Cloud will then create the environment (this takes just a few minutes).
Unlike rehosting solutions which need vendor-proprietary application servers, Heirloom applications deploy to open industry-standard Java Application Servers.
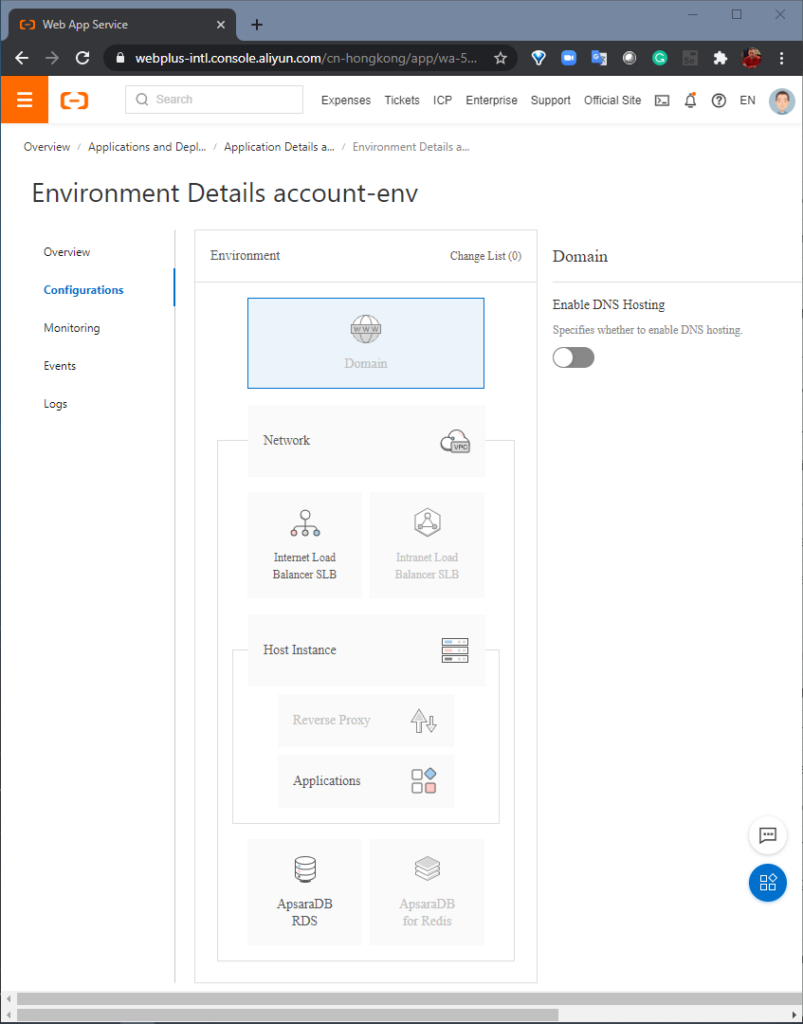
STEP 2: Configure. Here, we add an “Internet Load Balancer”, which will allow multiple client connections to the application to retain persistent sessions to multiple instances. Next, we create an “AsparaDB RDS” database, which is populated by a powerful data migration toolkit (included in the Heirloom SDK) that migrates mainframe datasets (VSAM, sequential, relational) to relational tables in the target database. The data transparency layer within the Heirloom Framework means that this can be done without needing to change the original application source code.
Configuration of the application environment is done natively within the cloud platform, and independently of the refactored Heirloom application.
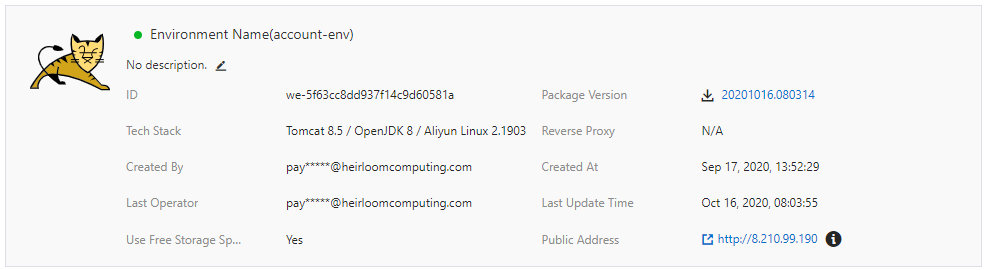
STEP 3: Execute. Out of the box, this particular application has 2 user interfaces that are both accessed via a standard browser.
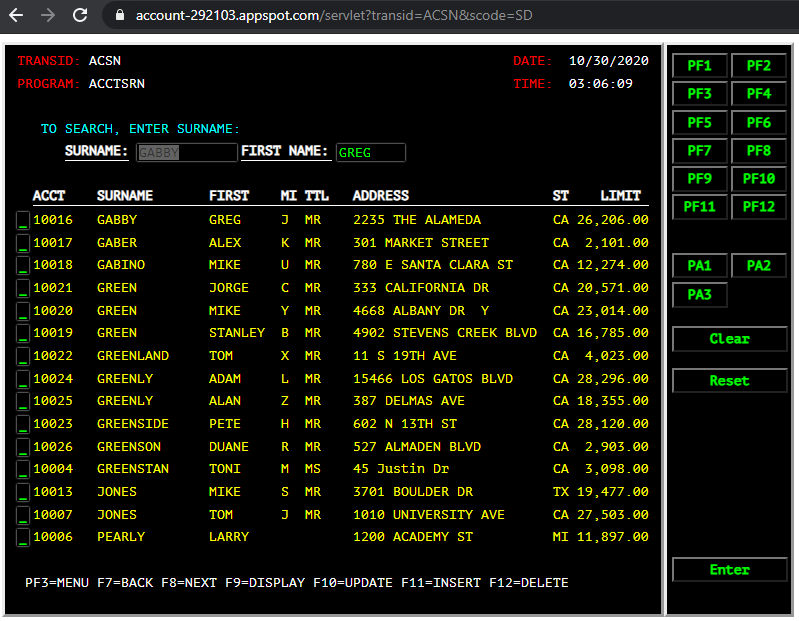
The first is the existing 3270-style interface that will function and behave exactly as it did on the mainframe. There is no additional application code required here. Just the original application artifacts, such as COBOL source, data, BMS maps, etc.
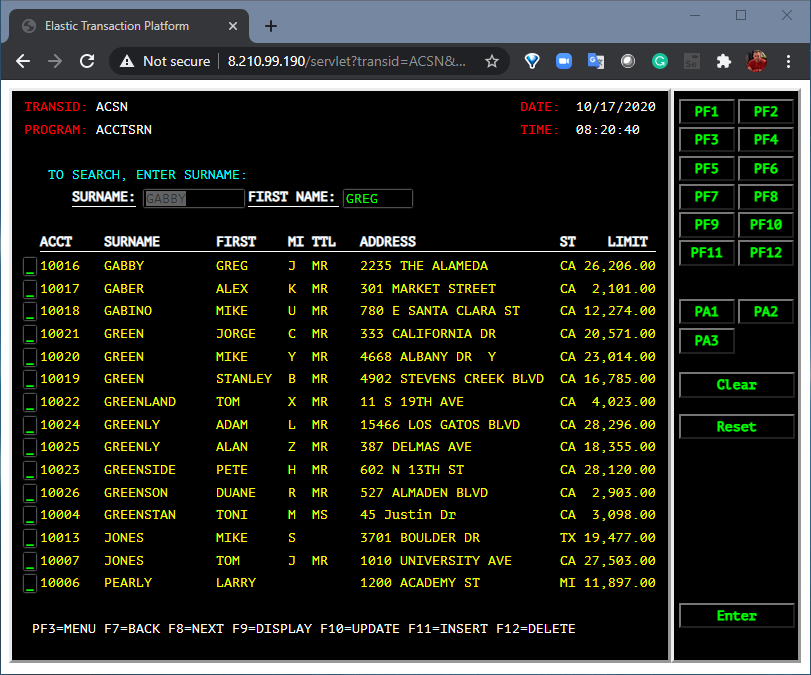
Heirloom applications are guaranteed to match existing function & behavior of the mainframe workload.
The second uses an additional application written in a Javascript UI framework called Ext JS (you can use others such as Angular, React, JQuery, etc.). What’s happening here is that the modernized UI (i.e. the Ext JS application) is interacting directly with the CICS transactions that have been automatically exposed via REST (this happens by default when refactoring with Heirloom). The application itself has not changed. It is still processing CICS transactions, but in such a way that they are now aggregated by the Ext JS application which renders them into a sortable table. Additionally, the new UI then uses the data to extend the functionality of the application (in this case, showing the address location of a particular customer using Google Maps).
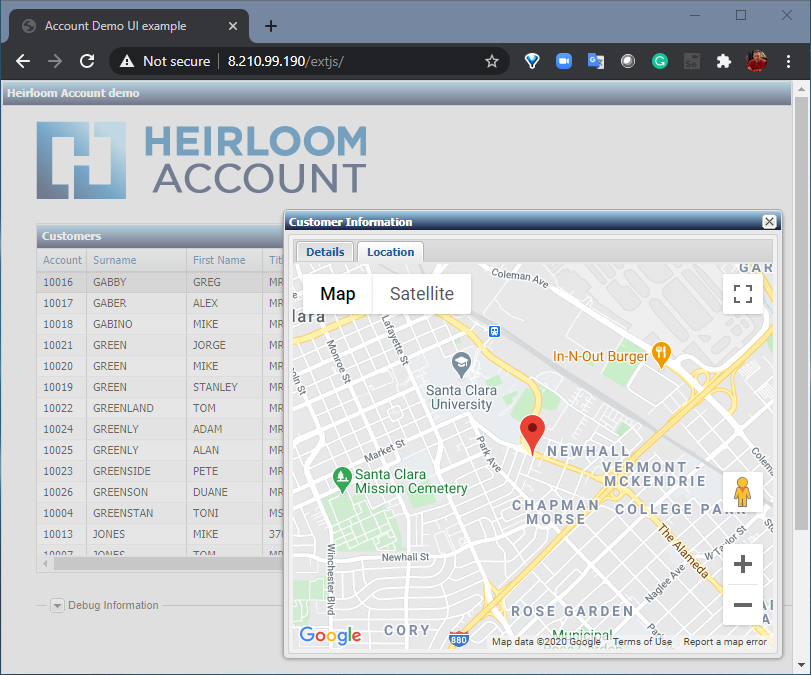
Not only is Heirloom the fastest most cost-effective way to refactor mainframe workloads to the cloud, they are instantly agile. UI modernization is just one possibility; others include breaking the monolith into microservices.
-
September 1st, 2020
Mainframe to the Cloud, the Right Way (Avoiding Gilded Cages)


The Elephant In The Room
After decades of evolution within a constrained ecosystem, mainframe applications are prodigiously complex & inflexible. And it’s not just the code … it’s the data, it’s the operational processes, it’s the security rules, it’s all the interfaces … in many variations and multiple combinations. Until recently, when cloud strategies were fervently discussed inside the rooms of Financial Services companies, Government departments, and elsewhere, the mainframe was the elephant in the room. Today, the progressive CIO has embraced the cloud and has sat the elephant at the table. So, what is the right approach that delivers the most value?

Reengineering?
Nope.
Look, I get the appeal. The idea that you can analyze a complex monolith to accurately extract business rules into an abstract model from which you can generate a brand-new shiny application with zero technical debt, is compelling. Having just written that sentence, I’m excited!
The problem is it just doesn’t work out that way. You will spend years paying your Systems Integrator to manually remediate low-fidelity generated code and write extensive test frameworks just to make it function as before. Then, if you survive, you are left with an entirely new application architecture that was imposed on you by your weapon of choice (MVC, anyone?) and a bunch of bespoke code written by a team who doesn’t even work for you. Guess what? That is technical debt — not only is it a prescriptive model rather than one aligned with your end-state, but it is also one that is less well understood than what you started with.
Let’s call it what it is:
Reengineering is a low-fidelity tools-based approach to rewriting an application that forces you to adopt an end-state that is not cloud-native and one in which you had no say in determining.

Rehosting/Emulation?
Nope.
I’ve been there, done that (prior company). More commonly known as “Lift & Shift”. With this approach, you are basically swapping the hardware. That’s it.
At the application layer, you are still dependent upon a vendor’s proprietary application server (just like you were before). You are still locked-in to the host language (predominantly COBOL, or perhaps PL/I or Natural — just like you were before). You are still entrenched in a scale-up application architecture that was first delivered by IBM in 1964 (just like you were before).
Let’s call it what it is:
Rehosting is an emulation-based approach that delivers no strategic value, locks you in to your technical debt, and forces you to adopt an end-state that is not cloud-native.

Replatforming?
Yep.
If you click on the rocket image to the right, you’ll see a 30-second video from Pivotal that does a great job explaining what replatforming is. This approach is also described as “automatic refactoring” by some.
At the core is a compiler that quickly and accurately recompiles online & batch mainframe applications (written in COBOL, PL/I, Natural) into 100% Java. Literally, compiling millions of lines-of-code in minutes, with guaranteed accuracy (just as you would expect from any compiler).
Refactored applications execute under any industry-standard Java Application Server (e.g. Apache Tomcat, Eclipse Jetty, Wildfly).
If you’re targeting the cloud and not deploying to a Java Application Server, you need to rethink your approach!
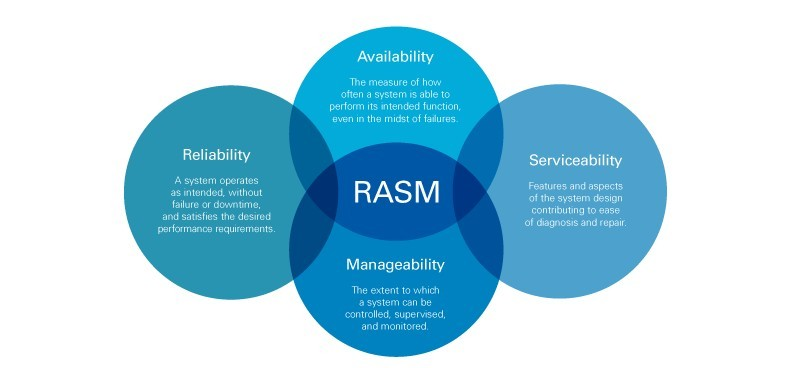
Executing under a Java Application Server means your application can be quickly & seamlessly integrated into your cloud-native platform of choice (including serverless environments). Which means it will scale horizontally on-demand, with high-availability (across multiple regions & zones), and with serviceability via centralized management & monitoring. Cloud-native Java applications deliver RAS(M).
Let’s call it what it is:
Replatforming is a fast & accurate compiler-based approach that delivers strategic value through creation of modern agile applications using an open industry-standard deployment model that is cloud-native.
Summary
Let’s say you’re attempting to make a road trip from Chicago to New York:
Reengineering will take you through the scenic route. You’ll never find a multi-lane roadway, and it’s likely you’ll visit all 50 states (yes, including Hawaii). When you arrive in Washington DC your vendor will tell you it’s been the trip of a lifetime.
Rehosting will put you on a highway/motorway but in the wrong direction, and you’ll end up in Milwaukee (the closest major city to Chicago). Your vendor will tell you that Milwaukee is the new New York.
Replatforming puts you on the fastest most-accurate route to New York. Once there, your vendor will ask you, where next? Large-scale cloud deployment? Smart-device integration? Breaking the monolith (into microservices)?
-
April 1st, 2020
99.999975% availability when migrating an IBM Mainframe COBOL/CICS application to the IBM Cloud with Heirloom.

Before you dismiss the headline, the availability number is not mine. It’s IBM’s.
All through my career, I’ve heard grey-beards talk of the fabled IBM Mainframe high-availability bar of “five nines” (no more than 5m16s of downtime in a year), so the assertion by IBM that “six nines” (no more than 7.9s of downtime in a year) could be achieved using the IBM Cloud (using Cloud Foundry) hooked me. Especially because with Heirloom, there was the high-probability that I could migrate a Mainframe COBOL/CICS application and execute it as a cloud-native application on the IBM Cloud.
Here’s IBM’s “how to” article: https://www.ibm.com/blogs/cloud-archive/2018/12/highly-available-applications-with-ibm-cloud-foundry/

As it turned out, following the article above was straightforward enough, and I migrated the COBOL/CICS application in about an hour to a cloud infrastructure that (by IBM’s calculations) would deliver a “six nines” SLA. Actually, if you round up IBM’s calculation, it’s “seven nines”, but I suppose some may view that pseudo-accounting as beyond the pale.
The basic design (from the article) is:
Multi-region deployment Two regions with two+ instances in each region with a global load balancer, providing an SLA availability of 99.999975%
Here’s a summary of the steps I took to complete the migration to a “six nines” infrastructure (prerequisites: an Heirloom Account and an IBM Cloud Account; installation of Heirloom SDK and IBM’s Cloud CLI tool).
The basic steps were: recompile, configure, package, set up cloud infrastructure, deploy & execute.
Recompiling the COBOL/CICS application into a Java .war package
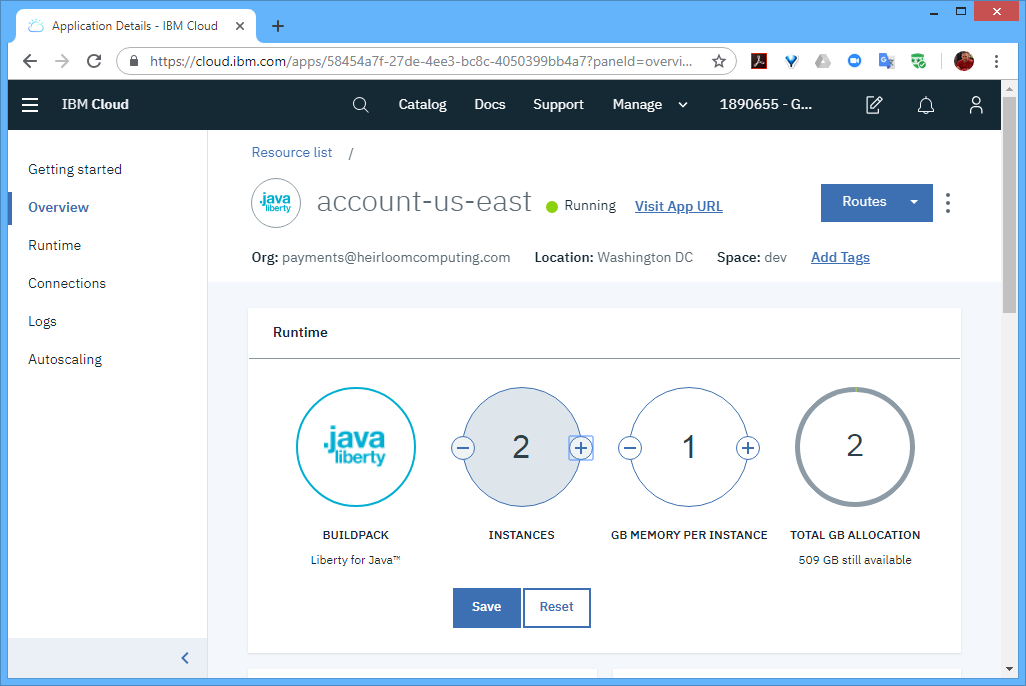
STEP 1: Recompile. Create a new project in the Heirloom SDK using the built-in “account” application. As soon as the project is created, it will automatically be compiled into 100% Java (this literally takes way less than 10 seconds), ready for deployment to any industry-standard Java Application Server (such as IBM Websphere Liberty).
STEP 2: Configure the deployment project. This is where I set up deployment information that tells the application things like how transactions ID’s relate to programs, and where the database is.
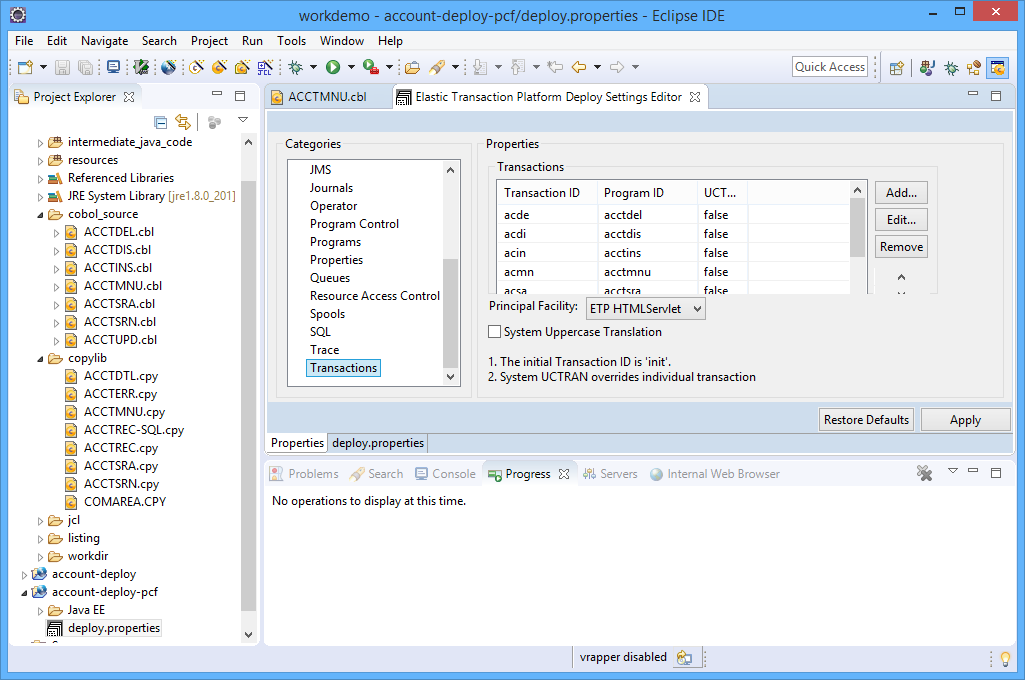
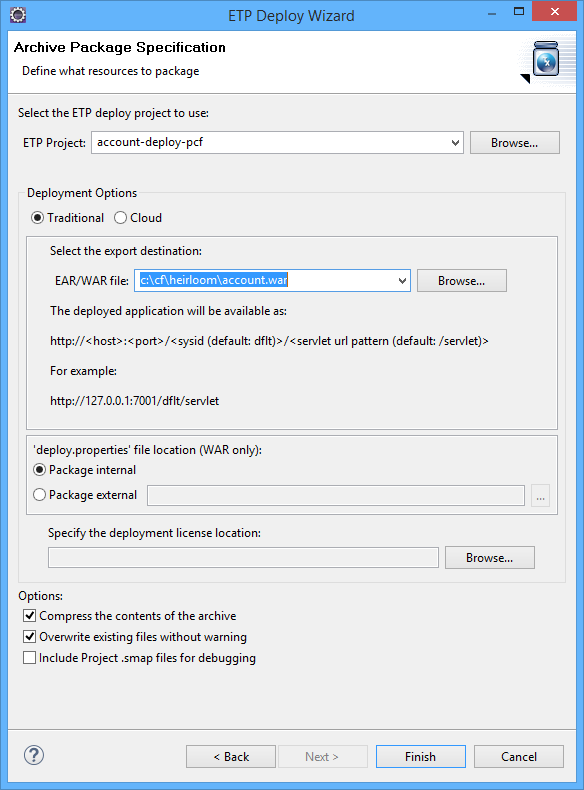
STEP 3: Package the application as a Java .war file — this is done using the built-in “Export Wizard” (again, this literally takes way less than 10 seconds). I now have an “account.war” package that contains everything I need to execute the application in exactly the same way as it used to run on the Mainframe. Only now, I can pretty much deploy it anywhere I choose. You already know where we’re going… to the IBM Cloud.
Setup, Deploy & Execute Application on the IBM Cloud
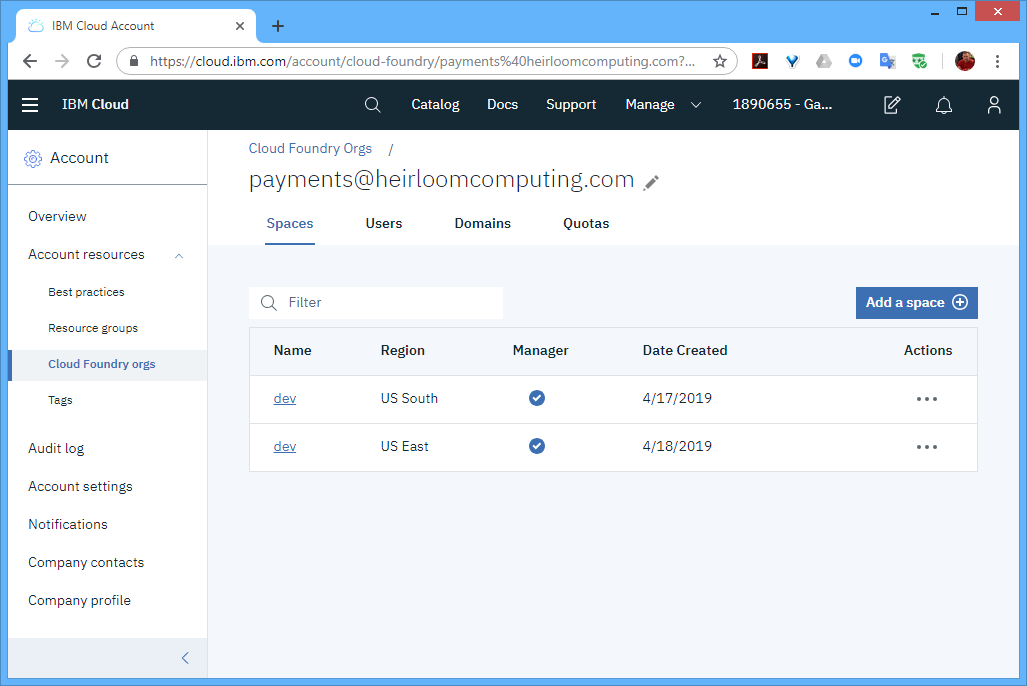
STEP 1: Setup. From the IBM Cloud Console, I needed to create 2 spaces within the organization (I named both “dev”). One space was located in the “US South” region, and the other space was located in the “US East” region.
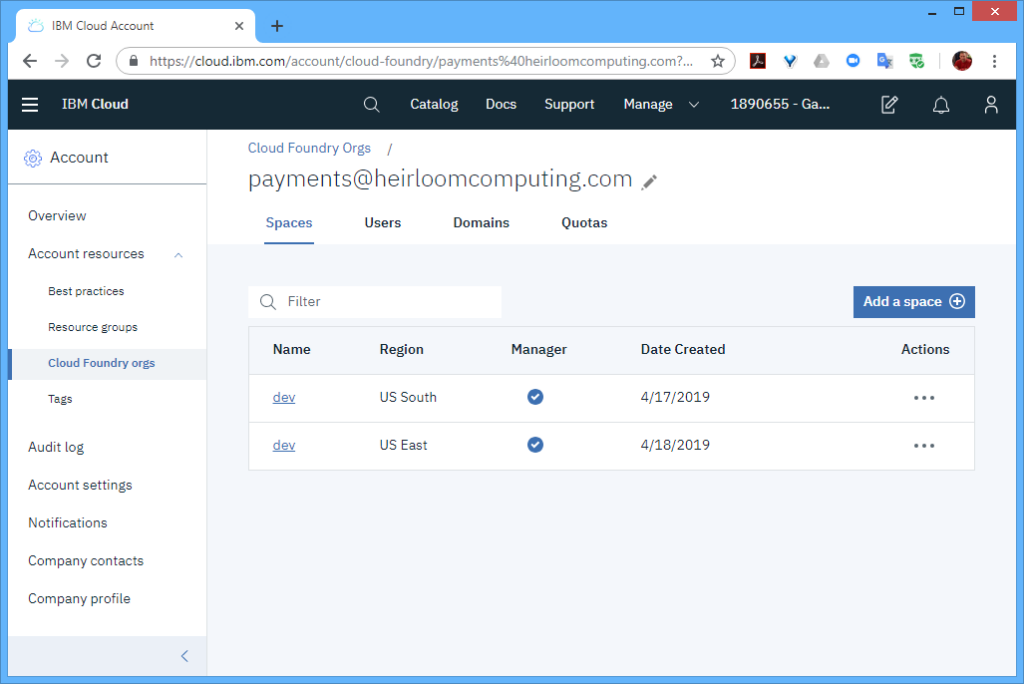
As per the article, I needed to have at least 2 instances in each region to achieve the “six nines” SLA. With Cloud Foundry, the multiple instances are automatically load-balanced for you, so there is no need for any additional setup within each region.
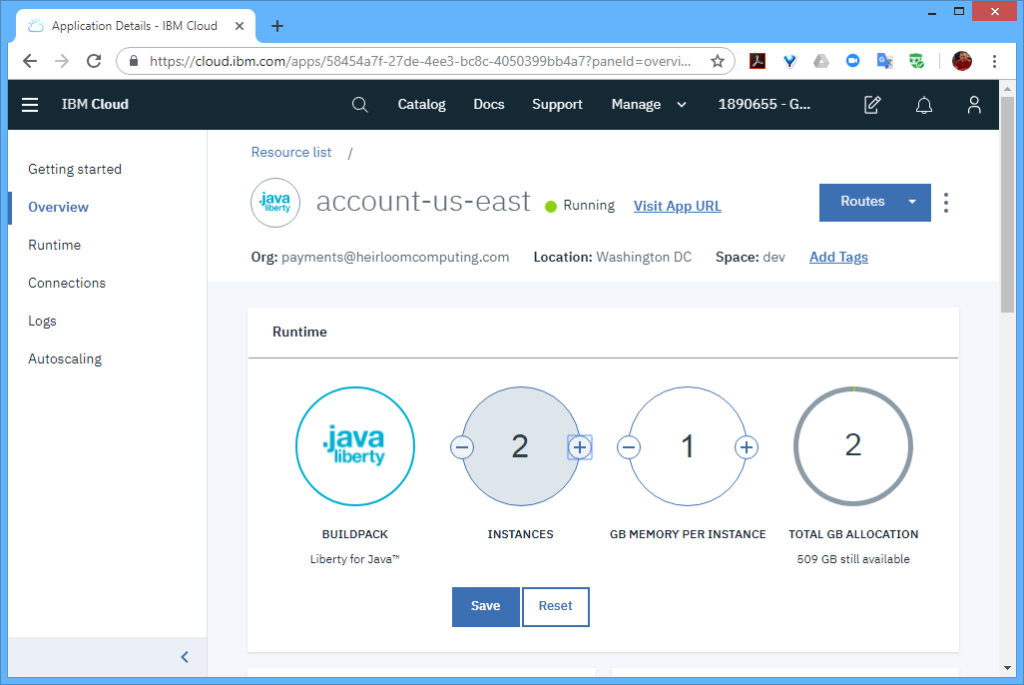
However, to distribute workloads across multiple regions (i.e. not just within a region), I also needed a “Global Load Balancer”, which I set to the “glb.heirloompaas.io” domain.
STEP 2: Deploy. With the cloud infrastructure in place, I switched to the CLI to deploy the “account.war” package to the 2 regions hosting the application infrastructure. These steps were for the “us-south” region (and repeated for the “us-east” region).
$ ibmcloud login $ ibmcloud target -o payments@heirloomcomputing.com -r us-south $ ibmcloud target -s dev $ ibmcloud cf push account-us-south -p account.war
That’s it! Now the application is ready to run on the “six nines” infrastructure.
STEP 3: Execute. Out of the box, this particular application has 2 user interfaces.
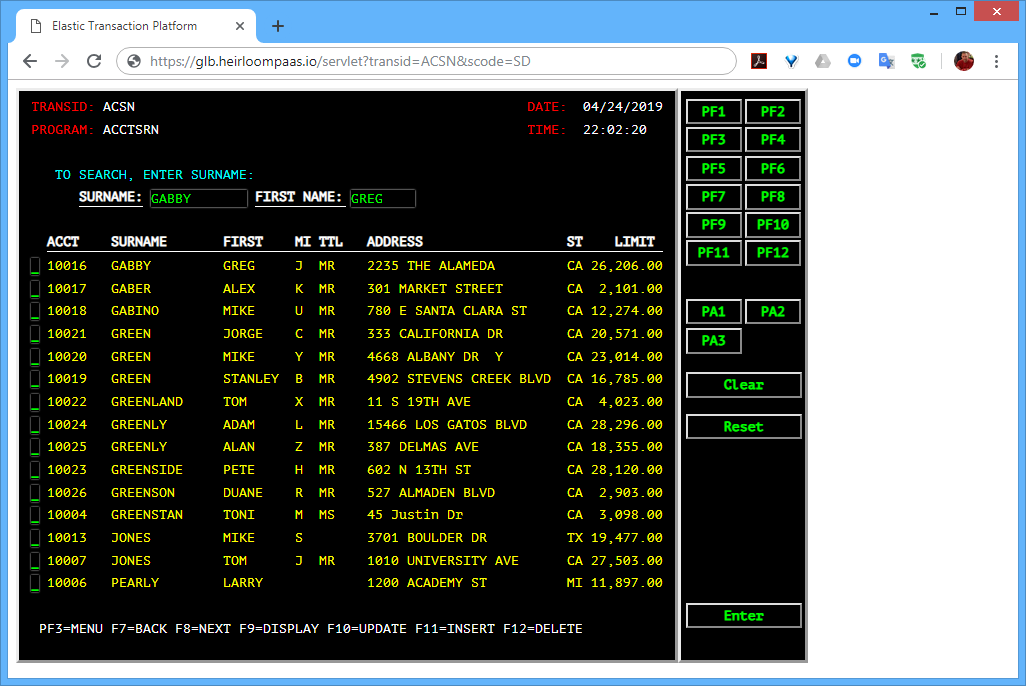
The first is the existing 3270-style interface that will function and behave exactly as it did on the mainframe. There is no additional application code required here. Just the original application artifacts (such as COBOL source, data, BMS maps, etc).
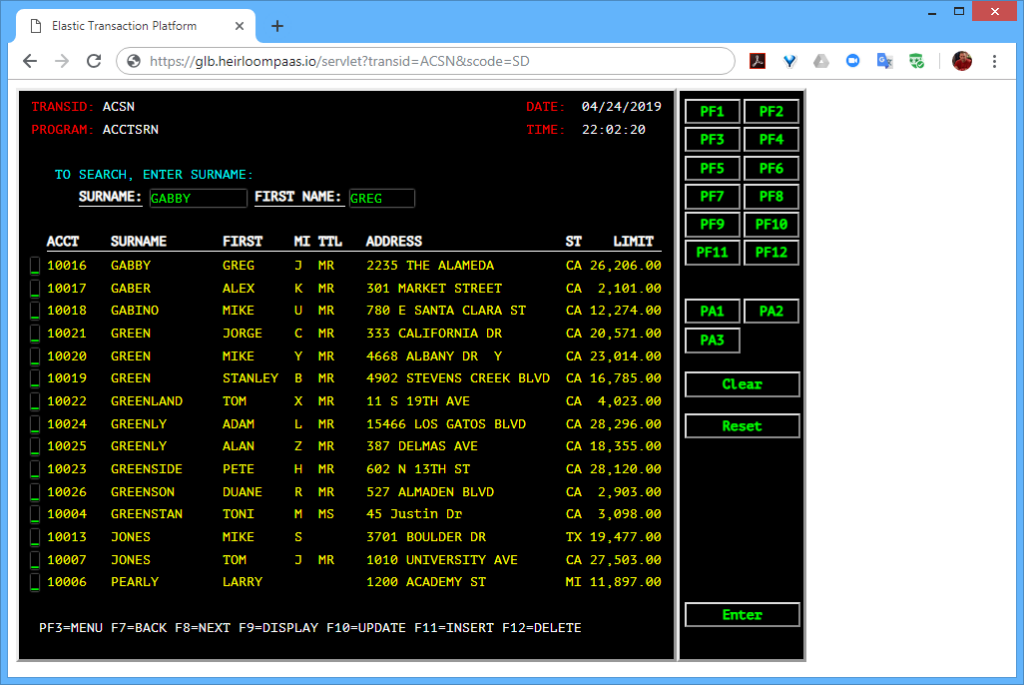
The second uses an additional application written in a Javascript UI framework called Ext JS (you can use others such as Angular, React, JQuery etc). What’s happening here is that the modernized UI (i.e. the Ext JS application) is interacting with the CICS transactions that have been automatically exposed via REST. The application itself has not changed. It is still processing CICS transactions, but in such a way that they are aggregated by the Ext JS application which renders them into a sortable table, and uses the data to extend the functionality of the application (in this case, showing the address location of a particular customer).
Summary
You can quickly & accurately migrate IBM Mainframe applications to the IBM Cloud with Heirloom.
Those applications are cloud-native — which means they can seamlessly leverage the full power of the IBM Cloud (such as “six nines” availability).
I didn’t highlight scalability in this article, but it should be obvious that since this is a cloud-native infrastructure, the deployed application can dynamically scale-out.
By exposing the business rules (such as CICS transactions) as REST services, they can easily be consumed by other applications. In this article I used an Ext JS application to modernize the UI, but the same approach can also be used to connect a smart-device, such as an Amazon Echo, or refactor them as microservices.
-
February 5th, 2020
Splice Machine Partners with Heirloom Computing to Modernize Mission-Critical Mainframe Applications
Partnership enables modernization of legacy applications to cloud-native targets with new data sources and injection of AI and machine learning, without rewriting them
San Francisco, Calif. – February 5, 2020 – Splice Machine, a provider of a scalable SQL database that enables companies to modernize their legacy and custom applications to be agile, data-rich, and intelligent, today announced a new partnership with Heirloom Computing to enable enterprises to modernize legacy, mission-critical, mainframe applications with Splice Machine’s intelligent SQL database. Businesses will benefit by at least an order of magnitude, from reengineering applications by hand, to refactoring at compiler-speed to an agile Java ecosystem on a modern data platform. In addition, enterprises will gain access to powerful new functionality by running their applications on the Splice Machine platform, such as leveraging real-time and historical data in analytics and injecting AI and machine learning into their applications.
For decades, mission-critical mainframe applications have anchored the banking, insurance, healthcare, and retail industries, as well as the public sector, all of which require heavy-duty, low latency transaction processing, where downtime would be extremely costly and unacceptable. But mainframe applications are being left behind as businesses strive to transform using distributed computing and public clouds. In large part, this is due to the perception that it’s overwhelming, even impossible, to modernize a mainframe application.
“The perception that mainframes can’t be modernized is outdated and misguided,” said Monte Zweben, co-founder and CEO of Splice Machine. “With Heirloom Computing’s cloud-native refactoring solution combined with migration to our scale-out SQL database, the barriers to mainframe modernization are broken down, resulting in reduced costs, increased business agility and entirely new business outcomes through the infusion of AI and machine learning.”
Heirloom® automatically refactors mainframe applications so they execute on any cloud, while preserving critical business logic, user-interfaces, data integrity, and systems security. Replatforming is a fast and accurate compiler-based approach that delivers strategic value through creation of modern agile applications that utilize an open industry-standard deployment model that is cloud-native.
“After decades of working with customers to first build – and now refactor – mainframe applications, we have now reached a tipping point where the benefits of refactoring are essentially business-centric and not solely technical,” said Gary Crook, president and CEO of Heirloom Computing. “The partnership with Splice Machine gives those enterprises that have been on the fence about moving off the mainframe yet another compelling reason to act. Splice Machine’s unique combination of scale-out, SQL and in-database machine learning will help breathe new life and intelligence into their prized mainframe applications.”
Heirloom, in combination with Splice Machine, offers enterprises the fastest way to modernize mainframe applications, enabling them to scale out on commodity hardware and leverage more modern, analytical techniques using an intelligent, SQL platform with in-database AI and machine learning.
-
January 1st, 2020
How to refactor an IBM Mainframe application as a highly scalable application on a fully managed serverless platform using Google Cloud App Engine.

Serverless computing offers incredible agility. In these environments, you can truly focus on building the application without the need to design, procure, deploy & manage an application infrastructure. Outside of the cloud, that takes a lot of work. Making it highly-available and able to scale out & back on-demand, makes the task an order of magnitude more complex (and expensive).

Jules Winnfield may think there’s no way for your trusted mainframe applications to exploit a serverless compute platform, but he would be wrong (not sure I’d tell him that though). Below, I will show you how it can be done, and you may even be surprised at how fast & easy it is. Of course, this is a demo, so the workload is pretty small, i.e. for illustration, but we have many clients where the workload is in the multi-thousand MIPS range.
Because we can deploy to cloud-native scalable platforms, the size of the workload is not typically a major factor for the transformation project.
Prerequisites: Heirloom Account and a Google Cloud Account. Let’s assume that you’ve taken the steps to download & install the Heirloom SDK, the Google Cloud Eclipse plugin, and the Google Cloud SDK.
Here’s how it’s done. Recompile, package, setup, deploy & execute.
Recompiling the COBOL/CICS application into a Java .war package
The key steps here involve using the Heirloom SDK to recompile the COBOL/CICS application into Java and packaging it into a .war package so it can be deployed to any industry-standard Java Application Server. I covered this in a previous article that targeted the deployment to Pivotal Cloud Foundry, so I won’t repeat the steps here.
Setup, Deploy & Execute … Google App Engine (GAE)
STEP 1: Setup. Setting up a new application in GAE is very easy.
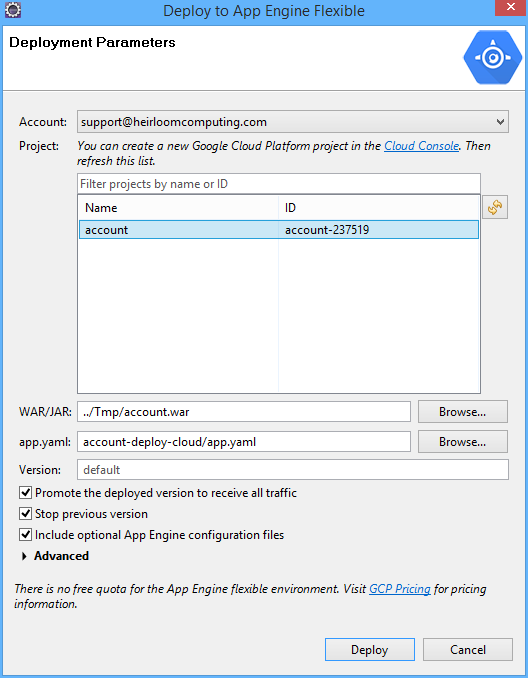
STEP 2: Deploy. We’re going to use the Google Eclipse plugin to login to our Google Cloud Account, select the application project (that we setup above), point it at the “account.war” package that we created using the Heirloom SDK, and deploy.
As soon as the deploy button is hit, the plugin creates a Google App Engine environment for our application. The specification for the environment is contained within the “app.yaml” file, which for this demo, looks like this:
runtime: java env: flex handlers: - url: /.* script: this field is required, but ignored env_variables: JETTY_MODULES_ENABLE: websocket network: session_affinity: true
The key items in this specification are “runtime: java” (i.e. give me an Eclipse Jetty instance) and “env: flex” (i.e. give me instances that are provisioned as Docker containers). The other item worth mentioning is “network: session_affinity: true”. This provides “sticky sessions” between the application client (which will be a web browser) and the application. Since online CICS mainframe applications are pseudo-conversational, maintaining the relationship between the client and multiple transactions within the same session is a requirement.
Once the deployment process is complete, a URL for the deployed service will be provided.
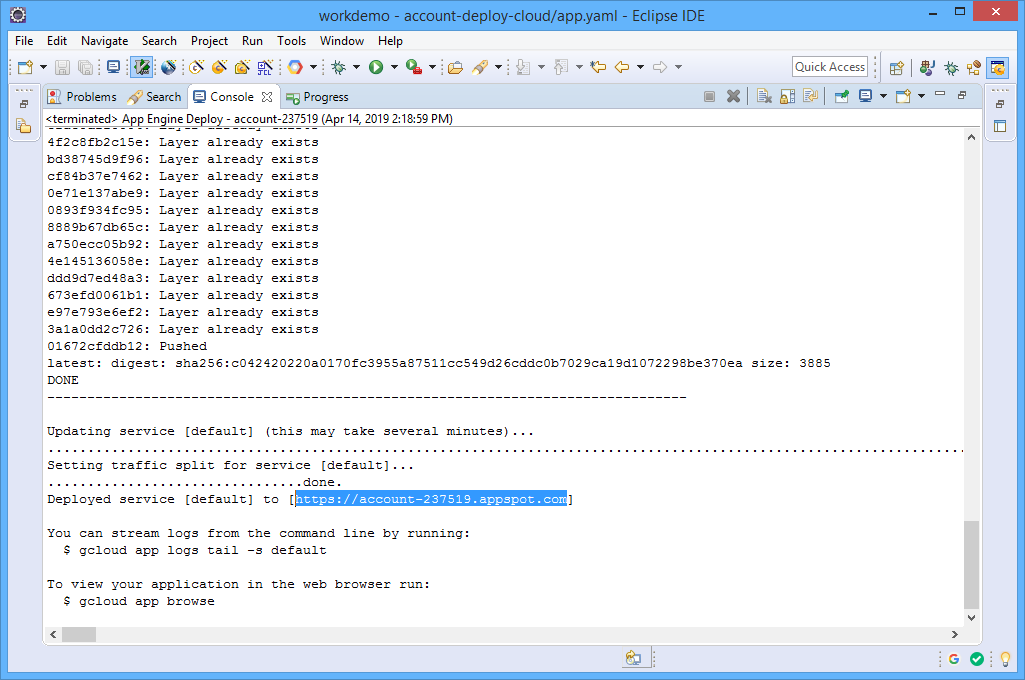
STEP 3: Execute. Simply grab the URL and point your browser at it.
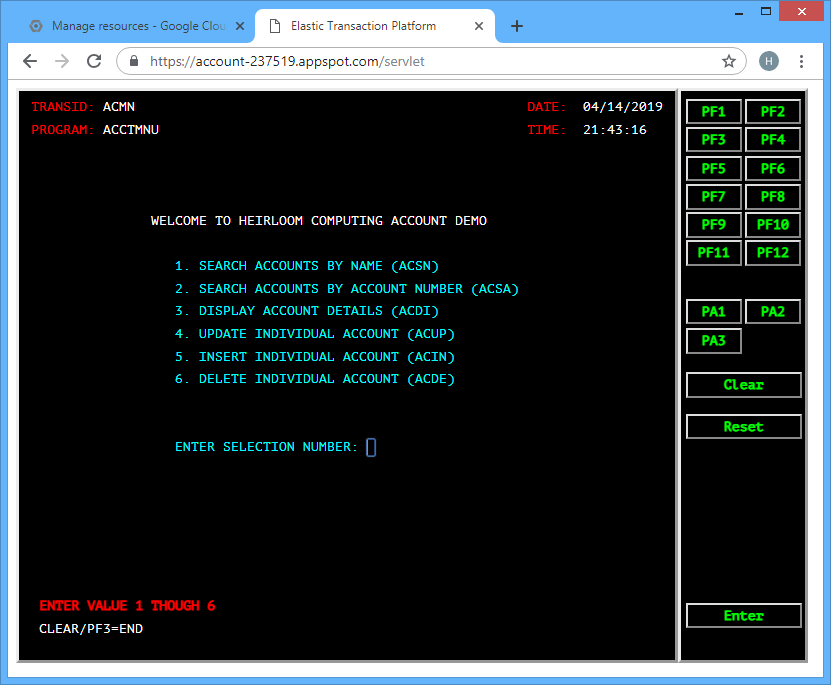
… enter 1, and …
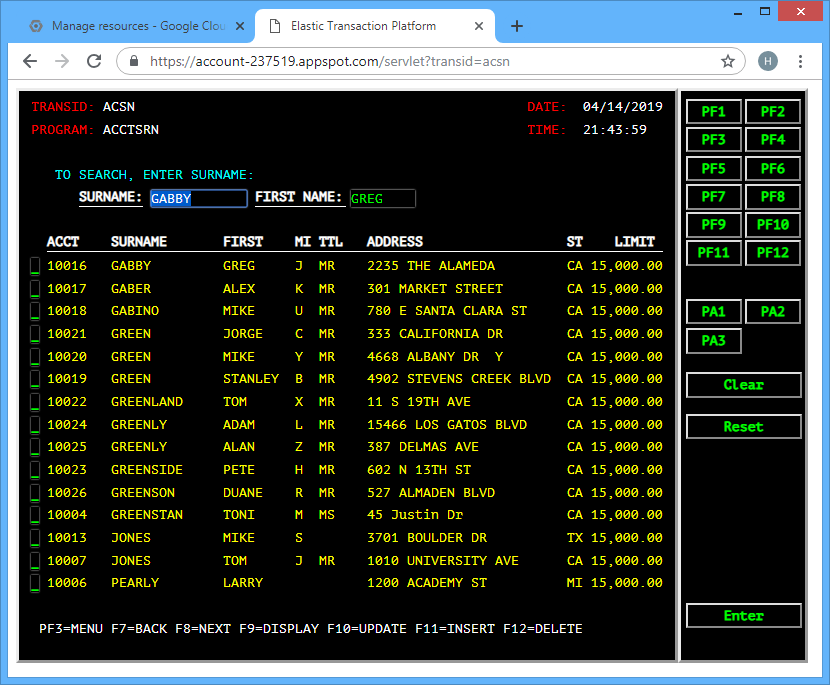
Obviously, there’s a lot of other capabilities built-in here, such as remote debugging, application monitoring, etc. With web applications, it’s often useful to review the server log, so as an example, this is how it can be done with GAE’s CLI:
$ gcloud app logs tail -s default
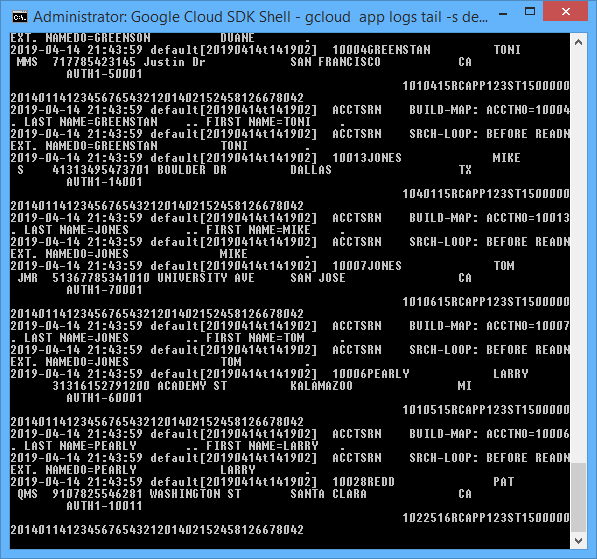
What you’re seeing here is all the COBOL DISPLAY (debug) statements that were emitted by the COBOL/CICS “account” application.
Summary
Serverless compute infrastructures can dramatically accelerate your IT and business agility (sorry, Jules).
Your mainframe workloads can exploit serverless compute infrastructures like Google App Engine (and others such as AWS Lambda, Azure App Service, OpenShift Knative, Pivotal PSF, …).
-
January 1st, 2019
15,200 MIPS on AWS with Heirloom (Autoscaling an IBM Mainframe Application to 1,018 Transactions/Second)

Movie: Plan 9 from Outer Space Introduction
If you are already muttering sweet phrases of disbelief at the headline, I understand, but hang in there!
The application used is a strict implementation of the TPC-C benchmark that was built for the IBM Mainframe using COBOL, BMS & CICS with a DB2 database. TPC-C is an online transaction processing (OLTP) benchmark that represents any industry that must manage, sell, or distribute a product or service.
Executive Summary
With Heirloom on AWS, IBM Mainframe applications that were monolithic, closed and scaled vertically, can be quickly & easily transformed (recompiled) so they are now agile, open and scaled horizontally.
This showcase clearly demonstrates the capability of Heirloom on AWS to deploy and dynamically scale a very large IBM Mainframe OLTP workload, with annual infrastructure cost savings of at least 90%.
The workload is deployed as an application that fully exploits the benefits of the cloud computing delivery model, such as application elasticity (the ability to automatically scale-out and scale-back), high availability (always accessible from anywhere at anytime), and pay-for-use (right-sized capacity for efficient resource utilization).
If your IBM Mainframe is an impediment to the execution of your strategic imperatives, contact us to learn how we can quickly & accurately transform your legacy workloads.
What We Did
First, we ran the TPC-C application on an IBM Mainframe to establish a baseline of transaction throughput per MIPS.
We then took the 50,000+ lines of the TPC-C application code & screens and compiled them (without any modifications) into 100% Java using the Heirloom SDK Eclipse plugin. The Java code was then packaged as a standard .war file, ready for deployment to any industry standard Java Application Server (such as Apache Tomcat). This process (from starting Eclipse to creating the .war file) can be done in 60 seconds (you can watch that happen in this video).
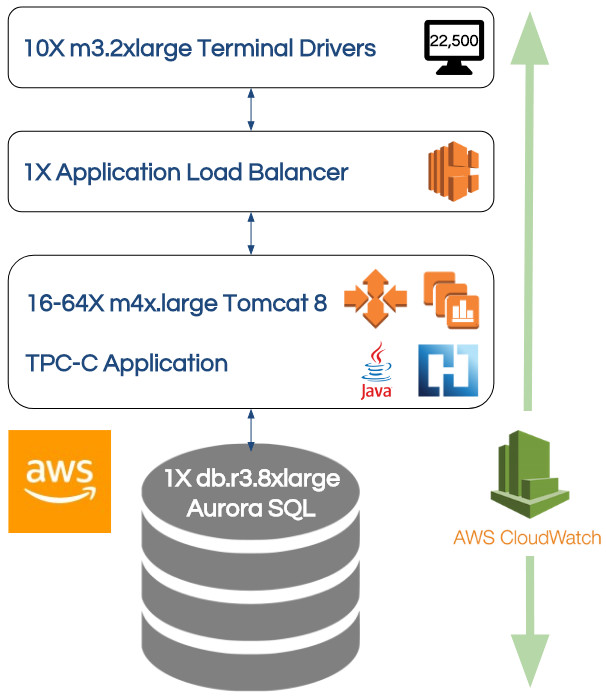
The .war file was deployed to the Amazon AWS platform described in the picture. The entire system runs inside AWS.
Briefly, the system comprises 5 primary layers:
- 22,500 simulated end-user terminals (think of 22,500 people simultaneously entering transactions into 3270 terminals).
- All concurrent transactions are distributed to application instances (in layer 3) by a single Amazon Application Load Balancer which automatically scales on-demand.
- The Heirloom TPC-C application layer is hosted in an Amazon Beanstalk environment consisting of a minimum of 16 Amazon EC2 instances (a Linux environment running Apache Tomcat). This environment automatically scales-out (by increments of 8), up to a maximum of 64 instances (depending on a metric of the average CPU utilization of the currently active instances). It also automatically scales-back when the load on the system decreases. For this application, the load is directly related to the number of active end-users on the system, and resource contention within the database. For enhanced reliability and availability, the instances are seamlessly distributed across 3 different availability zones (i.e. 3 different physical locations).
- The database (consisting of millions of rows of data in tables for districts, warehouses, items, stock-levels, new-orders etc) is hosted in an Amazon Aurora Database (which is both MySQL and PostgreSQL compatible).
- The application monitoring layer is provided by Amazon CloudWatch which provides a constant examination of the application instances and the AWS resources being utilized.
Execution Requirements
A valid TPC-C run must strictly adhere to the following primary requirements:
- All terminals must be operational before measuring transaction throughput (the “Warmup Time”).
- The system must run without error for a minimum period of 2 hours. This isn’t simply about getting all the terminals online and processing transactions. The design of TPC-C increases load on the database over time (including punishing table scan operations).
- At the end of the benchmark, response times on transactions in the 90th percentile range must be < 5s.
The Results
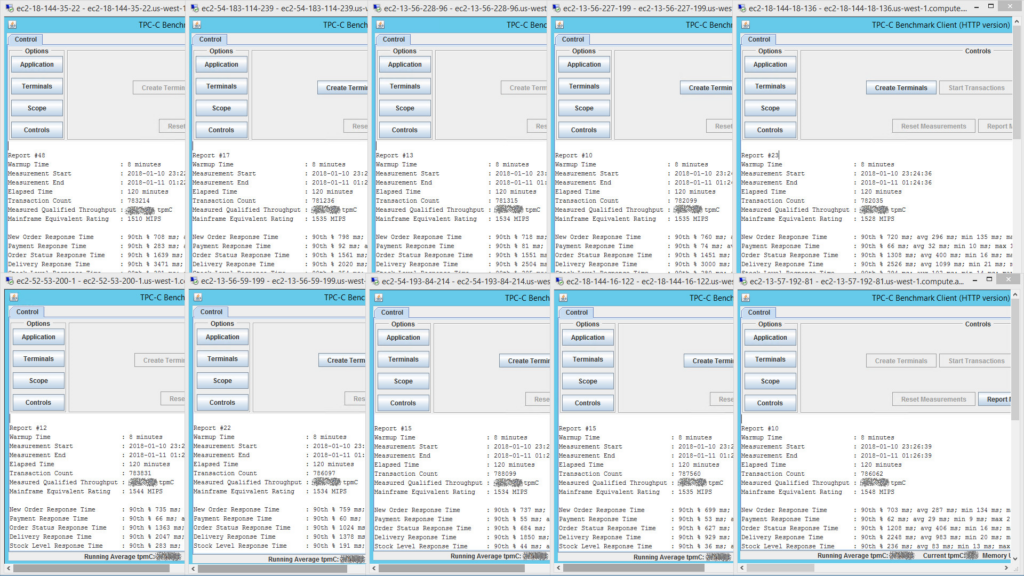
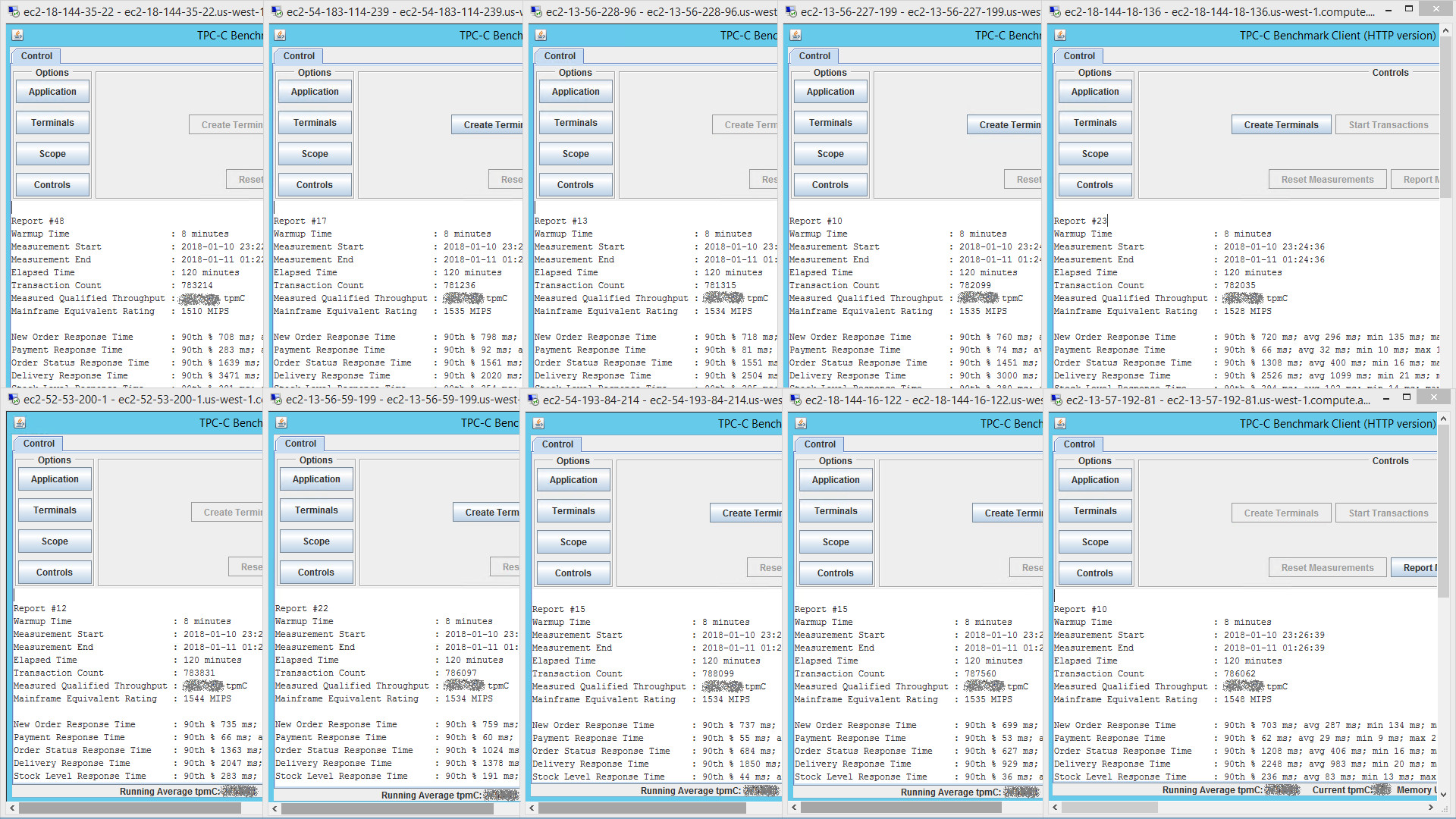
This image is of the 10 terminal drivers (each simulating 2,250 end-users) reporting results at the end of the TPC-C benchmark run. To see a bigger version of the image, right-click and open the image in a new tab.
All terminal drivers run in parallel, with each measuring transaction throughput for 2,250 terminals. These are added up to provide a total MIPS equivalent rating of over 15,200 MIPS.
The application workload (at peak scaling) was distributed over a total of 144 CPU cores (see details in FAQ below), which yields ~105 MIPS per CPU core. This is historically consistent with our client engagements, and a useful “rule of thumb” when looking at initial capacity planning.
Over the duration of the run, approx 7,820,000 end-user transactions were submitted.
7,820,000 / 128 minutes (incl. warmup time) / 60 = 1,018 transactions per second.
These are definitely not micro-transactions, so the transaction rate is mighty impressive. Especially considering the average response time for all transactions after 2 hours was still in the sub-second range.
Anticipatory FAQ
Why TPC-C?
Benchmarks from vendors are notoriously skewed. Pretty much, worthless.
TPC is an independent organization that has become an industry standard for measuring transaction throughput.
Why Heirloom?
Heirloom is the only platform that automatically refactors mainframe applications (online & batch) so they execute on Java Application Servers while preserving critical business logic, user interfaces, data integrity, and systems security.
The transformed application can continue to be developed in the original host language (COBOL, PL/I, JCL, etc), or in Java, or in any combination. You decide based on your objectives.
Why AWS?
Heirloom actually works on multiple clouds such as Pivotal Cloud Foundry, Google Cloud Platform, Microsoft Azure and Red Hat OpenShift, but we have had outstanding support from our partner Amazon in delivering this compelling mainframe-to-cloud showcase.
AWS provides an amazingly agile platform for easily deploying and managing auto-scaling workloads in a secure, reliable & available infrastructure. Powerful software services are aggregated to defined end-points that are seamlessly distributed to physical infrastructure in multiple data centers.
Can you provide more information on the AWS configuration?
Amazon lists EC2 instance types as having a number of vCPU’s. A vCPU is a virtualized core, not a physical core. However, a reasonable approximation is that 2 vCPU’s is presented from a single (hyperthreaded) physical CPU core.
i.e. 2 vCPU’s = 1 CPU core. We’re going to stick with physical CPU cores from here.
The scalable application layer (i.e. all the Tomcat Java Application Servers) consisted of a maximum of 64 m4x.large instances, each with 2 CPU cores. 128 in total.
The database layer (i.e. Amazon Aurora) was running on a single db.r4.8xlarge with 16 CPU cores.
So, excluding the terminal drivers (which in the real-world would simply be a browser tab on each end-users PC) and the load balancer, we have a system that can scale to a configured maximum of 144 CPU cores.
Why are the tpmC numbers masked in the results?
Reporting tpmC numbers without independent validation from TPC is a bit of a gray area, so we’ve erred on the side of caution and blurred it out. We’ve used an implementation of the TPC-C benchmark (because of its real-world characteristics) for comparative purposes only.
What about batch workloads?
Heirloom can scale batch workloads as well! It provides native support for JCL with its integrated Elastic Batch Platform (EBP) service. It has built-in clustering capabilities and integrates with various scheduling platforms via RESTful interfaces, including another service of Heirloom called Elastic Scheduling Platform (ESP). EBP runs on any standard Java Application Server and so seamlessly integrates with the AWS environment just as easily as the OLTP service.
Did you tune the IBM environment?
No. Neither did we tune the AWS environment. It’s certainly possible that tuning the mainframe environment could yield a better improvement than tuning the AWS environment, just as the reverse scenario is also possible. This is where benchmarking can get extremely contentious and extremely expensive. Respectfully, we’re not going there, as our assessment is that it will not fundamentally change the value proposition.
We use MSUs to size our IBM Mainframe, how does that relate?
MSU is a consumption-based measure and MIPS is a capacity-based measure, so hard to precisely compare. However, a reasonable “rule of thumb” is if you have a fully-utilized 6,000 MIPS mainframe, you would be consuming approximately 1,000 MSUs (i.e. a ratio of 6:1).
What’s the annual cost?
AWS
The vast majority of the infrastructure cost resides in the application and database layers. There are other costs such as load balancing and network traffic, but they are not relatively significant.
Let’s make the assumption that we’re running at the maximum configured capacity and 24×365 (which is unlikely). At peak load, we were using 64 m4.xlarge instances in the application layer, and 1 Aurora db.r4.8xlarge instance for the database.
Application layer (m4.xlarge): 64 * $0.20/hour * 24 * 365 = $112,128
Aurora database layer (db.r4.8xlarge): 1 * $4.64/hour * 24 * 365 = $40,646
Let’s add 10% (it’s definitely less than this) to cover other AWS costs. Other than the licensing cost of Heirloom, all the other software is included.
This gives us a total annual cost for the infrastructure of $168,050.
IBM Mainframe
We’re going to use some Gartner data that is in the public domain for this.
In 2009, Gartner figured out the total annual operating cost per IBM Mainframe MIPS was $4,496. In 2012, that number had reduced to $3,566, equivalent to an approximate reduction of 8% annually. Extrapolating that number through 2017 would give us a total operating cost per MIPS of $2,350.
15,200 MIPS * $2,350 = $35,720,000
In 2012, Gartner stated that hardware made up 14% of the total cost, and software made up 44% of the total cost. i.e. 58% of the total.
For 15,200 MIPS, this gives us a total annual cost for the infrastructure of $20,717,600.
That’s a pretty stark contrast to AWS (and this comparison doesn’t even factor in the staffing, automation, and maintenance cost benefits that are heavily in favor of the AWS infrastructure).
How much further can you go?
There is no indication of any significant constraints with increasing the capacity of the application layer. There’s tons of room to utilize more instances and much larger instance types.
Ultimately, the constraining factor with TPC-C (and OLTP workloads generally) will be the database. We have not yet leveraged the currently largest available Amazon Aurora instance (which is 2X bigger than the one we used in this showcase). From our work creating comparisons with other smaller Aurora instance types, it scales extremely well, so we would expect to see a significant increase in throughput.
We’re also looking forward to utilizing the upcoming Aurora Multi-Master release (which supports scale-out for both reads and writes).
-
September 1st, 2018
Breaking the Monolith: Creating Serverless Functions (Microservices) from an IBM Mainframe Application (Done In 60 Seconds)

A scene from the movie: Gone In 60 Seconds (Touchstone Pictures & Jerry Bruckheimer Films) Square Pegs in Round Holes
I understand; you may already be skeptical. The application modernization arena has not done itself any favors with years of vendor misdirection and misleading claims (permeating from whitepapers and glossy write-ups that attempt to recast tired proprietary technology as modern & relevant — square pegs in round holes). We encounter that hurdle with every new client. Often, they are exasperated; so we simply show them exactly how we modernize their code using open software and the sense of mistrust quickly evaporates, replaced by the understanding that Heirloom can make their trusted legacy applications, agile. In the same vein, I am going to show you how Heirloom can take a function from a monolithic IBM Mainframe COBOL/CICS application and deploy it to a serverless environment as a microservice (using AWS Lambda coupled with the recent release of AWS Lambda Layers).
What is Heirloom?
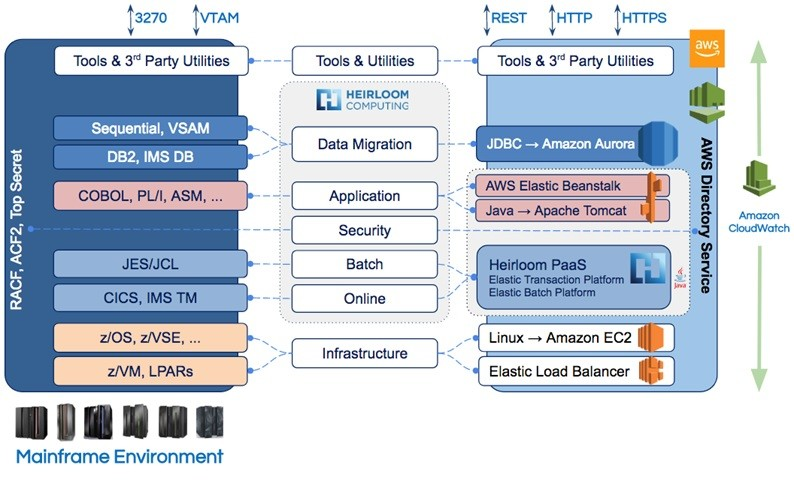
Heirloom is already the industry-leading solution for refactoring IBM Mainframe applications to the cloud. It is the only solution that was built for the cloud, delivering cloud-native deployment by automatically & accurately transforming online and batch COBOL & PL/I applications to 100% Java.
In 2018, we worked with Amazon to refactor an industry-standard TPC-C transaction processing benchmark written in COBOL/CICS from the IBM Mainframe to AWS Elastic Beanstalk, delivering 1,018 transactions per second — equivalent to the processing capacity of a large 15,200 MIPS IBM Mainframe — with a dramatically reduced annual infrastructure cost of $365K vs $16M. You can read more about this showcase on Amazon’s APN site.
What is Serverless Computing?
Beyond instance-oriented infrastructures (like AWS Elastic Beanstalk), are serverless compute/store infrastructures (like AWS Lambda) that deploy discreet functions as microservices.
With serverless computing, you run code without provisioning or managing servers (zero administration effort), required resources are continuously scaled (automatically), and costs are only incurred when your code is running (measured in sub-seconds).
Microservices provide a model for delivering high-quality applications that are agile, scalable, and available.
Breaking an IBM Mainframe Monolith into a Microservice
In the video below, we start with an IBM Mainframe COBOL/CICS application that has been refactored with Heirloom and is now running under a local instance of a Java Application Server (Apache Tomcat). The next steps taken with Heirloom to extract, create and deploy the microservice are:
- Create the application layer: The Heirloom “Facade Factory” is used to extract and refactor the “Get Credit Limit” logic from the monolithic application, as a discreet callable function (encapsulated in a Java jar package), and deployed as an AWS Lambda Layer (this is the “getAccount” application layer).
- Create the AWS Lambda service: We overlay a simple AWS Lambda service sample with the code to call “getAccount” with its defined inputs, and process the output (this is the “AccountLimit” service).
- Construct the microservice: Finally, we associate the “AccountLimit” service with the “getAccount” (application) layer and the Heirloom AWS Lambda (runtime) layer.
The combination of these components represents the entirety of the microservice stack. More simply stated, the stack looks like this:
[client] — invoke the microservice [AWS Lambda Service: AccountLimit] — service interface [AWS Lambda Layer: getAccount] — facade and extracted function [AWS Lambda Layer: Heirloom runtime] — Java framework for executing mainframe appsThe Heirloom AWS Lambda runtime layer provides everything you need to deploy microservices derived from your online and batch IBM Mainframe applications. It’s much more than just a language runtime — it’s a mainframe platform (implemented as a Java framework).
In summary, Heirloom can quickly & accurately refactor your IBM Mainframe applications to agile cloud infrastructures like AWS Elastic Beanstalk, Azure App Service, Pivotal Cloud Foundry, Red Hat OpenShift & Google Cloud Platform.
It can also enable & accelerate your transformation from monolithic application architectures to microservices running on serverless computing infrastructures like AWS Lambda.